

Raul Palma leads the data analytics and semantics department at the Poznan Supercomputing and Networking Center (PSNC), where he coordinates the R&D activities and the center’s participation in various EU projects around these topics. In this guest post for the metaphacts blog, Raul explains how knowledge graph technology can address data integration challenges in the agri-food sector, showcasing it through a few use cases. He describes how he leveraged metaphactory to build a domain-specific application - FOODIE - that delivers intuitive access to distributed, heterogeneous data sources and allows end users to extract meaningful insights.
FOODIE is an agriculture knowledge hub delivered as a Web application built on top of metaphactory Knowledge Graph platform. The application enables an integrated view and access over multiple datasets which have been collected from various and heterogeneous sources relevant to the agriculture sector, transformed, and published as Linked Data / in a Knowledge Graph.
Context
Farm management is a complex process that involves multiple activities carried out by farmers and other stakeholders, who have to manage multiple and heterogeneous data sources collected and generated through various applications, services and devices.
The rapid advances of IoT technologies, AI and Big Data, among others, have boosted the adoption of smart farming practices, which emphasizes the use of ICT in the farm management cycle to exploit the available data.
The explosion of data availability, however, has led to new challenges. Data is usually available in different sources, in different formats, and represented according to different models, thereby hampering data interoperability and integration. The lack of integrated data access, in turn, hinders the full potential of value creation based on all the available data, and the development of smart services and applications supporting the decision making processes. Thus, a key challenge to realise the smart farming vision to its fullest is to combine/integrate those different and heterogeneous data sources in order to support the decision making processes.
Knowledge graphs provide a flexible and efficient solution to address some of those challenges. In particular, they can provide an integrated view over (initially) disconnected and heterogeneous datasets, through the interlinking of different entities, typically by applying Linked Data principles, and in compliance with any privacy and access control needs. Accordingly, different agri-related projects (e.g., DEMETER, OPEN IACS, SIEUSOIL, etc.) are generating and using knowledge graphs based on Linked Data to support large scale harmonization and integration of a large variety of data collected from various heterogeneous sources in order to provide an integrated view on them.
Built on top of the metaphactory Knowledge Graph platform, the FOODIE application supports the integration of multiple and heterogeneous datasets, vocabularies, and taxonomies, and serves multiple use cases - from collections of agri-related indicators to deliver insights into crop distribution, through farm productivity and sustainability benchmarking, to aquaculture monitoring.
The main data source of the FOODIE application is a Virtuoso triplestore with over 1 billion triples from more than 100 datasets, which makes it one of the largest public semantic repositories related to agriculture, recognized by the European Commission Innovation Radar as the “Arable Farming Data Integrator for Smart Farming”.
The FOODIE application comprises several custom templates and pages that showcase different user scenarios for knowledge discovery, navigation, exploration and/or analytics allowing end users and stakeholders of the agri-food sector to extract meaningful and actionable insights that can support them in taking more economically and environmentally sound decisions.
On top of that, the FOODIE application showcases some scenarios that address hybrid information needs, where agri-related services (available via a REST API) can be accessed and queried as virtual RDF graphs. Thanks to the Ephedra engine in metaphactory, these virtual graphs can be easily connected with other linked datasets on-the-fly via federated queries, thus providing a virtual integrated access to hybrid information sources.
Use Case: Monitoring Agri-related Indicators
The EU-funded CYBELE project aims to generate innovation and create value in the domains of agri-food by implementing Precision Agriculture (PA) and Precision Livestock Farming (PLF) methods, and empower capacity building within the industrial and research communities associated with these domains.
One of the use cases of the CYBELE project hosted on the FOODIE application focuses on enabling access to a large collection of both open and derived data from Netherlands for use in agri-food applications (by Wageningen Environmental Research), and to connect it with other open and widely used EU vocabularies (such as AgroVoc or Eurostat) so that it can interoperate with other services, and be connected with datasets based on such vocabularies.
Insights derived from this data are relevant for a variety of stakeholders such as:
- Organisations collecting or validating agri-related indicators, e.g., paying agencies advisors who are looking for more granular views of crops;
- Advisory organizations, e.g., organizations looking to gain insights into the distribution of crops in their region;
- Researchers, e.g., looking to find potential demonstration farms (farms willing to participate in the trial and validation of innovative solutions/technologies on their fields);
- Producers, e.g., looking to identify clusters of crops, etc.
The data from the Wageningen Environmental Research is available via the AgroDataCube service, which exposes a REST API including resources for fields, crops, meteo, and soil data, among others. In the FOODIE application, metaphactory's Ephedra query engine is used to access the service as a virtual RDF graph via federated SPARQL queries that are embedded in the web components used in the application pages for this use case.
So how does a concrete interaction example look in this use case? Let’s say a user from the Netherlands who works for an advisory organization wants to see the fields in his region with a particular Agrovoc crop (e.g., Maize). He starts typing the crop name in the search box. Note that since the information is connected to semantic concepts, he can even type in Dutch (mais), and he will be able to find the corresponding crop.
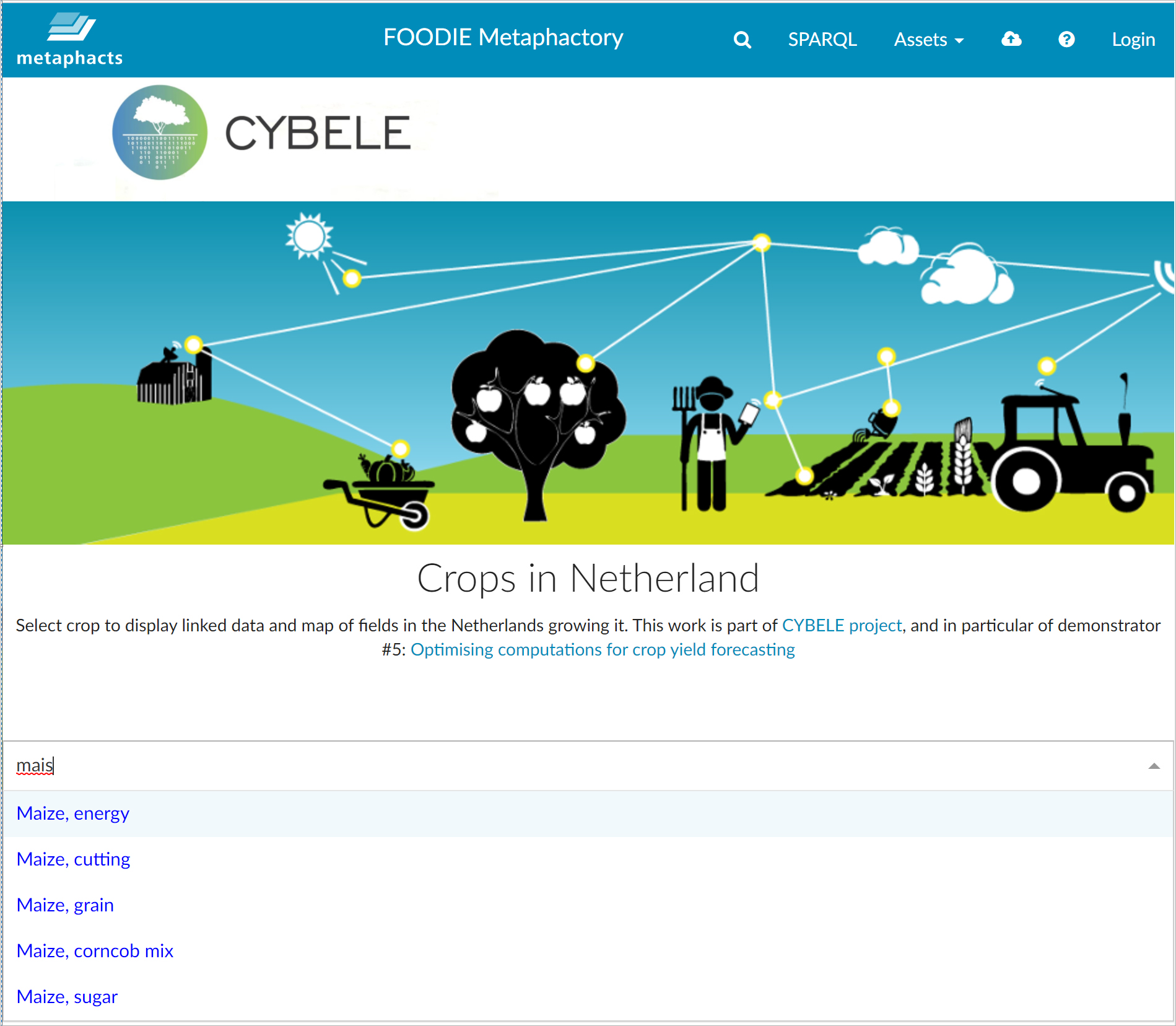
End-user search for a specific Agrovoc crop, incl. multilinguality support
He selects one of the Maize crops, e.g., "maize, cutting". In the page template he can see the information about this entity, and a tab to show the fields with that crop on a map. In this tab, the user can also see all the information about the Agrovoc Maize concept, the broader term of the selected concept, including what is it used for, how is it produced, pathogens, etc., as well as matches of the term Maize in other vocabularies/datasets.
In the map below, the user can see the fields with this crop, and when she/he clicks on one of those fields, field information such as perimeter, code, etc. is displayed.
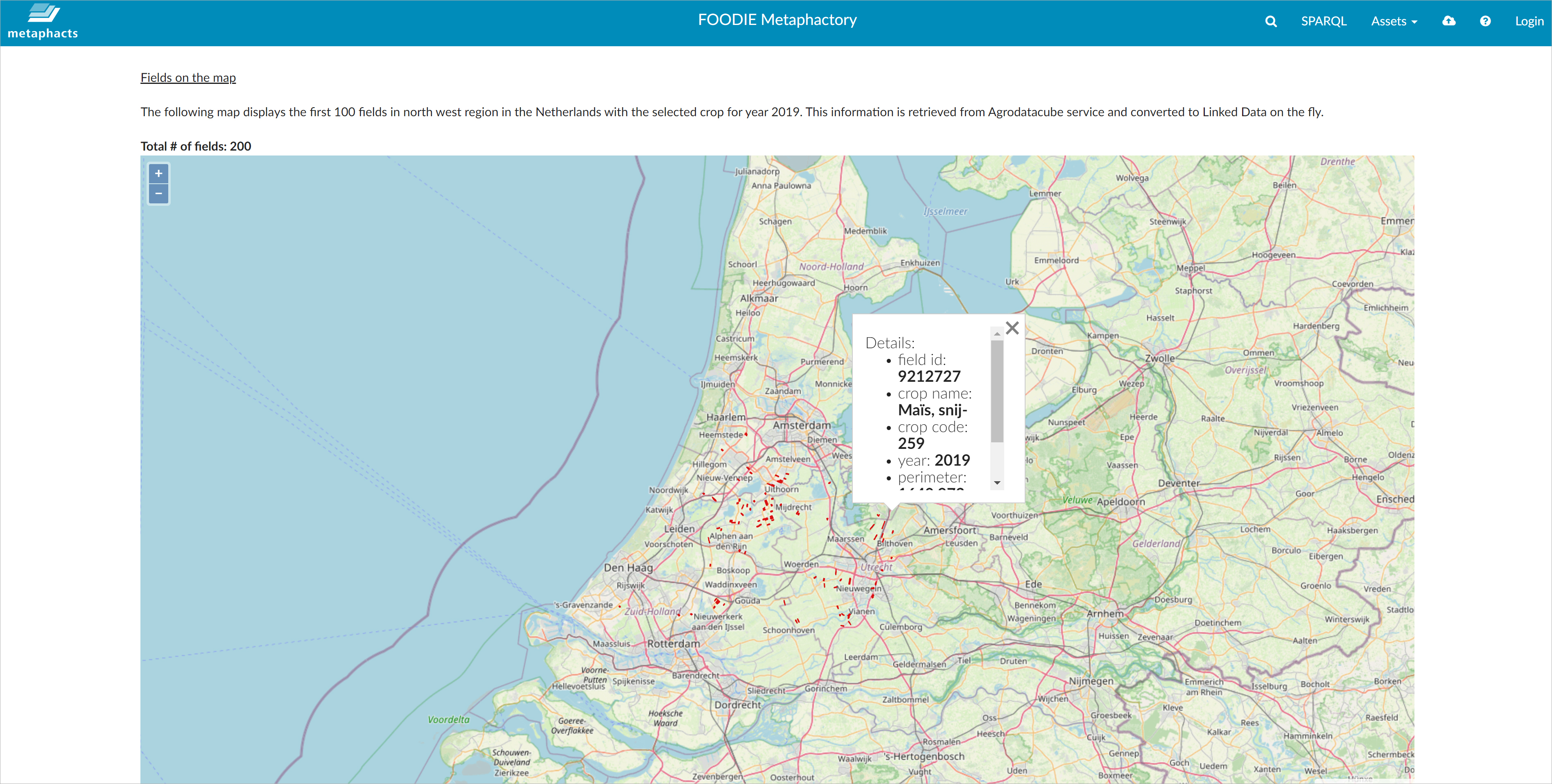
Map visualization of particular crops in a specific region
Follow this link to have a look at this use case live in the FOODIE application: https://metaphactory.foodie-cloud.org/resource/:AGROVOC-crops
Use Case: Farm Productivity and Sustainability Benchmarking
Another EU-funded project that hosts some of its use cases on the FOODIE application is the DEMETER project. DEMETER’s goal is to lead the digital transformation of Europe’s agri-food sector through the rapid adoption of advanced IoT technologies, data science and smart farming, ensuring its long-term viability and sustainability.
One of the use cases addressed in the DEMETER project aims to enable the benchmarking on the productivity and sustainability performance of the farms. This involves monitoring and comparing different conditions and parameters affecting such indicators, and collecting the data and integrating it in a unified layer accessible by a Decision Support System. Such information is relevant for:
- Organisations collecting or validating agri-related indicators, e.g., paying agencies advisors who want to have a complete view of agri-related indicators at different levels and identify poorly performing regions;
- Advisory organizations, e.g., looking to gain insights of agri-indicators in their region;
- Researchers, e.g., looking to find regions with poor performance, or to research conditions;
- Producers, e.g., interested in identifying high-demand regions and their challenges to customize their offer, etc.
Some of the key datasets necessary for the benchmarking include statistical data from the EU FADN (Farm Accountancy Data Network) and Eurostat. These datasets, however, are not integrated and are not interoperable. FADN for example can be downloaded as CSV files, while Eurostat is also available as CSV but additionally provides instructions on how to transform them into RDF. Hence, a first step for this scenario involved the transformation and publishing of both FADN and relevant Eurostat datasets as Linked Data (using Linked Data publication pipelines that can be re-executed whenever new updates are available), including establishing connections between them and other relevant datasets. Then, via metaphactory, these datasets can be navigated and visualized, and via the SPARQL endpoint they can be queried in an integrated manner.
The FOODIE demonstrator for the DEMETER project will allow end users to, for example, retrieve farm profitability in a specific region and compare this data with their own farm profitability, or compare yield of their farm crop with respect to average yield in the region. While the demonstrator is still in development at the moment, you can already navigate the datasets via https://metaphactory.foodie-cloud.org/resource/?uri=http%3A%2F%2Fpurl.org%2Flinked-data%2Fcube%23DataSet
Building a Knowledge Graph for Agri-Food
The FOODIE application has evolved over several years to cover multiple use cases in multiple projects. With the implementation of each use case, we noticed a recurring process to get things up and running. This led us to the design and implementation of "Linked Data pipelines", which automate as much as possible the processes to carry out the necessary steps to transform and publish different input datasets from various heterogeneous sources as Linked Data. In the DEMETER project, a command line tool and a Web service exposing these pipelines is under implementation. A high-level view of these pipelines is depicted in the diagram below.
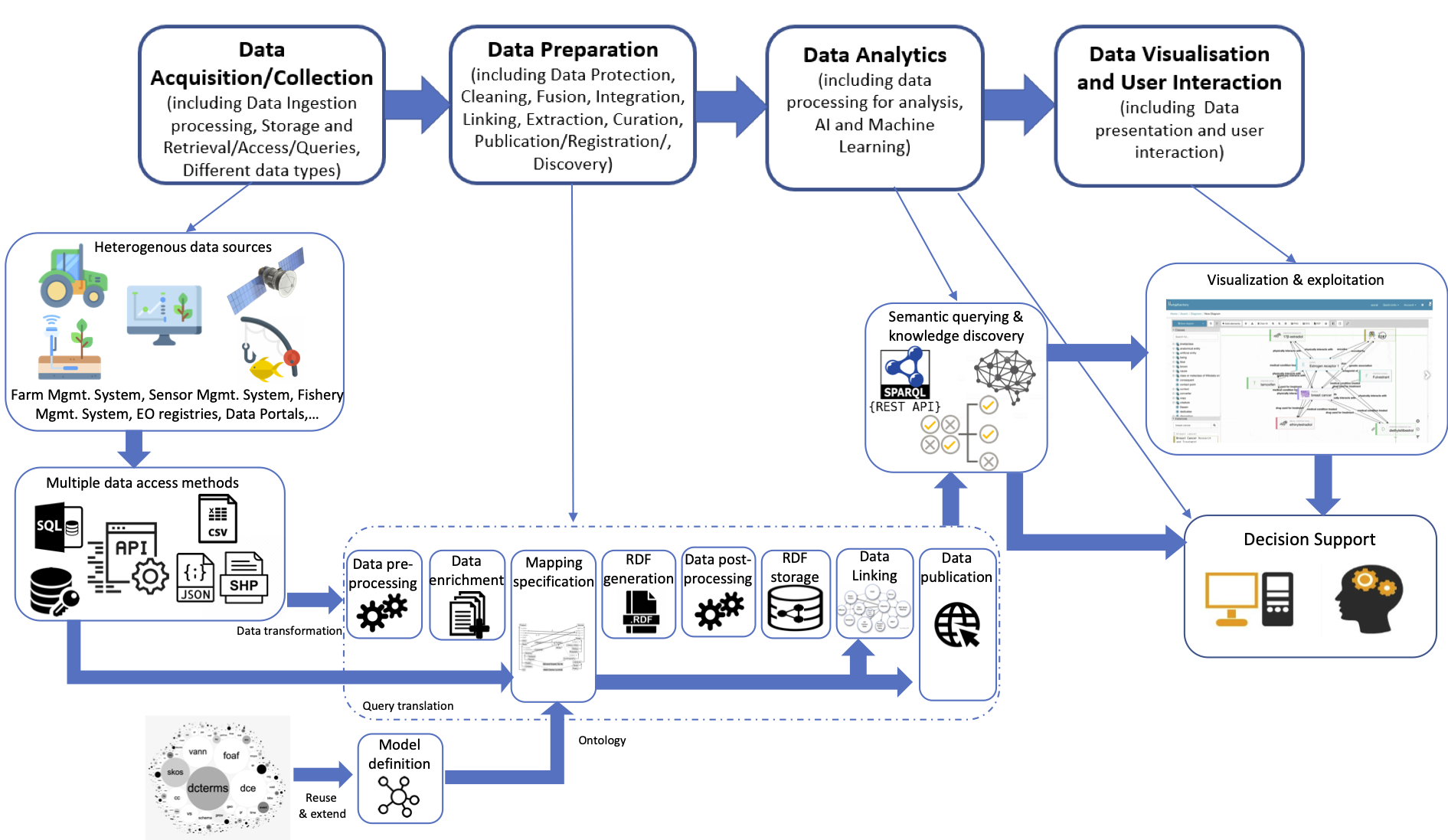
In general, the first step after collecting and preprocessing (if needed) the source data, was to define the actual use case we were trying to address, be it crop production planning, policy definitions, or machinery management, and the specific user needs we were looking at. In parallel, we started looking at relevant datasets that could deliver insights for our use case. As a next step, we identified and selected target ontologies and vocabularies to model the use case at hand, or we modeled the ontology ourselves following best practices in ontology engineering and always trying to reuse existing standards and/or well-scoped ontologies/vocabularies whenever possible.
For instance, one of the main goals of DEMETER project was to provide the "Agriculture Information Model - AIM" [2], which aligns and extends well-known ontologies and vocabularies related to agriculture, to be used as the basis for enabling data integration and the semantic interoperability of heterogeneous systems. AIM was built following a modular and layered approach facilitating its extension and maintainability. The diagram below shows a partial view of the AgriFeature module of AIM.

Once the ontology was in place, we specified data mappings between the source and the target models, and transformed and integrated the relevant datasets (e.g., farm data, data about field boundaries, crop map, yield records, erosion zones, water bodies, soil data, meteo data, vegetation data, altitude data, sensor data incl. readings of IoT devices on tractors, etc.).
Some of the data sources were integrated as virtual RDF graphs using the hybrid federation services provided by metaphactory’s Ephedra. The ability to integrate services on the fly with the Ephedra federation engine and to expose data in a knowledge graph without having to transform it again whenever it changes is particularly useful for dynamic sources of data.
As a last step, we defined the user interface using metaphactory’s template mechanism and extensive set of Web components, allowing users to interact with and consume data from the Knowledge Graph. By reusing metaphactory’s rich set of customizable search, query and visualization components (structured search, tables, charts, geographical maps, etc.), and customizable templates and pages, we were able to set up an end-user application much faster than building everything from scratch.
Today, the FOODIE application hosts a variety of use cases, in addition to the two use cases described in detail above. Some examples include:
- An aquaculture monitoring use case that focuses on catch records in Norway and allows users to identify the most profitable places to catch on the map, the best timing for cathing, the regions with more catches and totals, which regions/areas might need protection to avoid overfishing, etc.
- An Earth Observation (EO) use case where information about planet Earth’s physical, chemical and biological systems is collected (e.g., from remote sensing technologies such as satellites and aerial sensors along with ground-based observations) with the goals of integrating data with other EU and world datasets and/or vocabularies (e.g., NASA concepts), and listing EO collections and visualizing the described EO products on the map. Various catalogues of EO products metadata are available. This scenario exposes the FedEO system, which provides a unique entry point to a growing number of scientific catalogues and services. FedEO exposes an Opensearch REST API that can return data in different formats (e.g., GeoJson).
A number of additional projects that plan to leverage metaphactory for the visualization and exploitation of data are in development already on the FOODIE application. Some of the datasets that are going to be showcased soon include:
- Soil data in Europe
- Land Parcel Information System (LPIS) data from all EU countries
- Land use data in Europe
- Agriculture indicators
To have a look at the FOODIE application and experience some of the use cases described here first-hand, feel free to have a look at our online system or install the FOODIE app which will also allow you to try some of the configurations yourself.
Footnotes
[1] Sørensen, Claus & Fountas, Spyros & Nash, Edward & Pesonen, Liisa & Bochtis, Dionysis & Pedersen, S.M. & Basso, Bruno & Blackmore, B.. (2010). Conceptual model of a future farm management information system. Computers and Electronics in Agriculture. 72. 37-47. 10.1016/j.compag.2010.02.003.
[2] Available via: https://github.com/rapw3k/DEMETER/tree/master/models
Upcoming publication: Palma R., Roussaki I., Döhmen T. et. al. Agricultural Information Model. In ICT for Agriculture Book. Springer.
Thank you, Raul, for your contribution to our blog and for demonstrating how knowledge graphs and metaphactory can be used in practice to solve address real-world use cases.
