
Publishing FAIR data in the humanities sector
Reference data is a crucial element of data curation in the cultural heritage and humanities sector. Using reference data brings multiple benefits, such as consistent cataloguing, easier lookup and interaction with the data, or compatibility with other data collections that use the same reference data. Overall, the use of reference data can support the publication of FAIR data - data that is findable, accessible, interoperable and reusable.
In museum collection management, for example, various thesauri can be used as reference data to ensure the accurate and consistent cataloguing of items in a controlled manner and according to specific terminologies. Thesauri exist for various areas of expertise. One example is the Getty Art and Architecture Thesaurus® (AAT) which describes the different types of items of art, architecture and material culture, such as "cathedral" as a type of religious building. Authority data has also been published to support the unique identification of specific entities such as persons, organizations, or places, for example, "Cologne cathedral" as a specific instance of the type "cathedral". Such authority data sources include The Integrated Authority File (GND) or the Union List of Artist Names® Online (ULAN) and are specifically important for disambiguating over entities with the same name, e.g., Boston, the town in the UK, and Boston, the city in the USA.
Digital humanities projects often combine several research directions and use materials that cover multiple disciplinary areas. This makes the implementation of reference data difficult, as several reference data sources need to be used to cover all aspects and facets of a project. Moreover, technical access to reference data is inconsistent, with systems using different interfaces and APIs, which makes integration challenging.
Advantages of an interconnected reference data system
Digital humanities projects that cross disciplinary boundaries need to rely on multiple, specialized data sources to ensure that data is captured accurately. Sources that cover wider domains, e.g., Wikidata, often lack the required level of detail, whereas individual specialized data sources that provide more details in specific areas often only cover very narrow subject domains. This means that several different sources need to be integrated to, for example, accurately describe terms, places, persons, institutions, etc. in one system. But accessing several sources is cumbersome, as stated before, and often compromises need to be made in terms of the number sources used or the number of entities for which reference data is used.
An interconnected reference data system can provide very clear advantages when it comes to entity disambiguation, contextualization or in multilingual projects. Reference data sources often contain links to other sources; for example, GND contains links to Wikidata, which in turn contains links to many other reference data sources. In an interconnected system, these links can be very useful in providing additional reference data or additional information about entities; this can help with, e.g., disambiguating between similar entities.
The Swiss Art Research Infrastructure's approach to reference data
The Swiss Art Research Infrastructure (SARI) provides unified and mutual access to domain-specific research data, collection data, digitised visual resources, and related reference data in the field of art history, design history, history of photography, film studies, architecture and urban planning, archaeology, history studies, religious studies, and other disciplines related to the visual studies, as well as the digital humanities at large.1
Through its services, SARI does not only provide a state-of-the-art research environment for teaching and research in the humanities, but it also enhances visibility and accessibility of Switzerland’s research and collection data.
The data produced within SARI is modeled to be interlinked with and act as a point of reference for other data sources. This is achieved by making data accessible and reusable, both on a technical level - by leveraging Linked Data principles - and on a conceptual level - through the implementation of the CIDOC Conceptual Representation Model (CIDOC-CRM) as the knowledge representation system. On a technical level, the system relies on using common identifiers provided by reference data - one of the key Linked Data principles - in order to link entities from different datasets. On a conceptual level, the information collected from museums, libraries, archives, etc. is interlinked under the same "umbrella" or general schemas defined with CIDOC-CRM, which helps maintain the intrinsic semantic value of this information and allows users to search across them.
Making entities identifiable with unique IDs and normalising and exposing data as Linked Data allows for the creation of truly interconnected datasets. Such networks of data which are open and reusable by others are key to avoiding the re-statement of information, the creation of data silos and the curation of individual sources; instead, they promote a more flexible (and yet authoritative) approach to publishing information.
SARI's Reference Data Service
SARI's Reference Data Service (RDS) was built using metaphacts software and offers a central data hub that hosts commonly used reference data sets such as ULAN, VIAF, etc. and also includes Wikidata when searching for people, places, events, etc.
The central system (so-called RDS-Global) hosts the canonical versions of the datasets and is maintained by the SARI team. It is accessible to researchers and other users using a Google-like search interface.
Additionally, research institutions can set up their own, local systems (so-called RDS-Local) for authoring of own research data, consuming data from the upstream RDS-Global system and - if desired - for publishing data back to the central repository and making it available for consumption and interlinking to other researchers as well. This system might be independent or act as a satellite to the RDS-Global hub.
Setting up an RDS-Local instance is described on GitHub. The required RDS client is available for free.
RDS Architecture
The following diagram shows the architecture of the RDS-Global system and how a local RDS system interacts with the central system. The various services delivered by metaphacts software and used in the RDS architecture are described in the following sections.
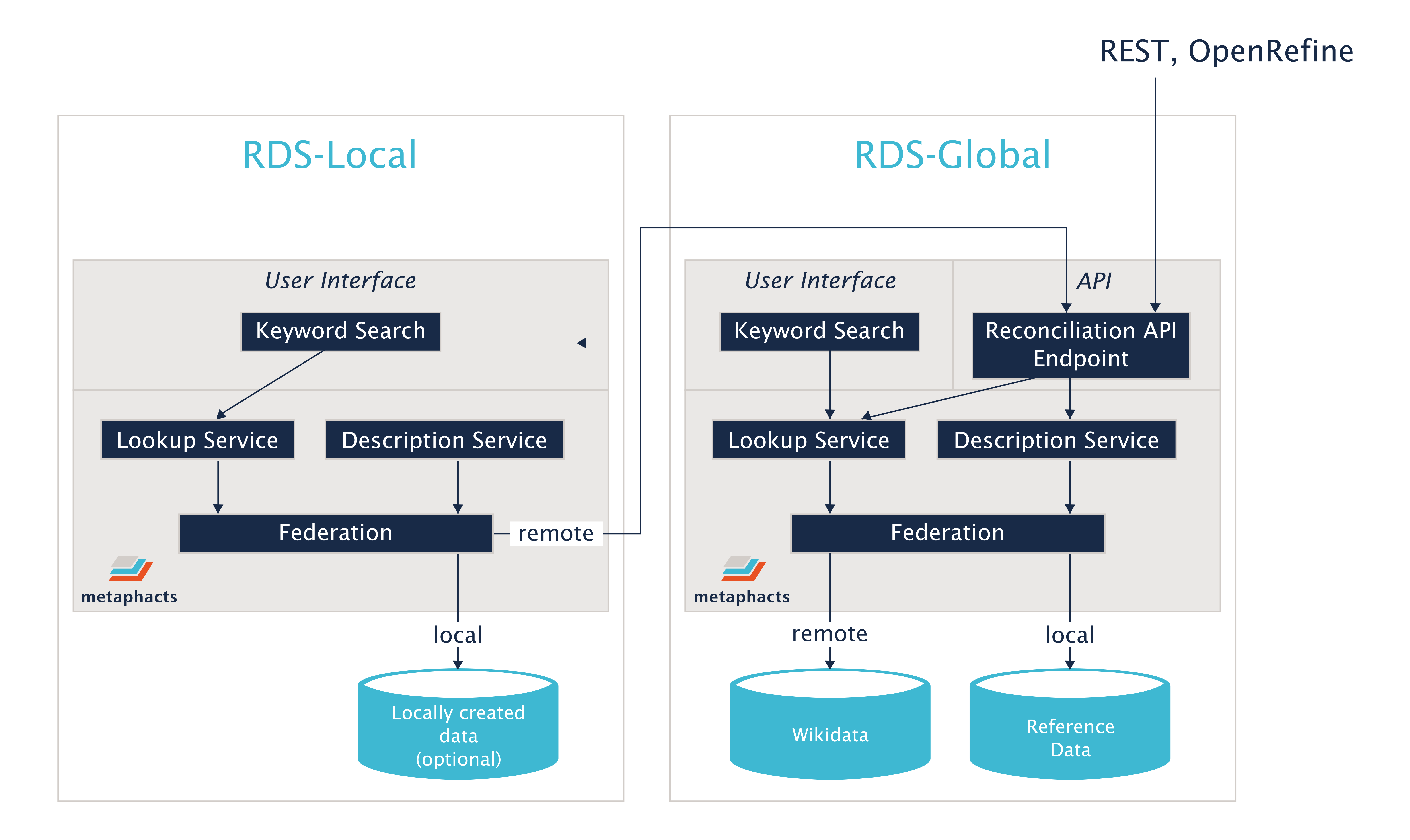
Keyword Search
Searching for canonical identifiers of entities – people, events, places, etc. – is one of the most important use cases of RDS. Consequently, the system needs to support fast keyword-based search and lookup within the hosted datasets. This was achieved using the Lookup Service which abstracts away the specific search syntax of the underlying database implementation and provides a unified interface for entity lookup.
The Lookup Service is integrated with various platform components and can also be addressed via a REST API based on the standardized Reconciliation API defined by a W3C community group. This allows for using the service not just from the RDS-Global and RDS-Local systems, but also from third-party clients such as OpenRefine.
Disambiguation based on descriptions
A keyword lookup by name often leads to ambiguous results with multiple possible matches. To support selecting the desired entity, the lookup candidates not only contain the entity's label but also a description. This description might sometimes be part of the dataset, but often there is no good pre-defined description readily available. The Description Service, developed to cater to a core need identified in RDS, allows for generating type-specific descriptions. For a person this might include the occupation, affiliation and birthday or lifespan whereas a place is typically better described by geographic references including the country or region.
Datasets and Federation
The datasets are organized in multiple named graphs, one per dataset. RDS also provides access to content from Wikidata, which is implemented as a federated, remote data source.
Google-like search and other lookup requests should provide search results from all supported datasets. To support this distributed setup with a local database and the remote Wikidata repository, the Lookup Service also supports federation. Any lookup request is sent to all datasets and external repositories and the results are combined.
Linked Data and Same-As
Being able to search in multiple datasets also supports another important feature: cross-linked entities. The datasets hosted by RDS have overlapping content. For example, a musician might be described in VIAF, ULAN, and also in Wikidata. Some datasets provide links to corresponding entries in other datasets that are used here to create cross-references to similar entries. Wikidata acts as a data integration hub by providing identifiers of an entity within many other datasets.
While this is the poster-child example for Linked Data in general, the identifiers provided by Wikidata are oftentimes not IRIs but rather numeric or textual IDs. With some additional processing, those references are turned into real links in the RDS knowledge graph. For performance reasons, these links are extracted in a batch operation and materialized in the RDS database.
When searching for entities, the result candidates from all datasets are aggregated based on those materialized links. Entities from different datasets that are considered identical are grouped together. The Google-like search will present them together and provide additional information from each dataset so that a user can choose the desired canonical identifier. A concrete example of how this works follows in the RDS Use Cases section below.
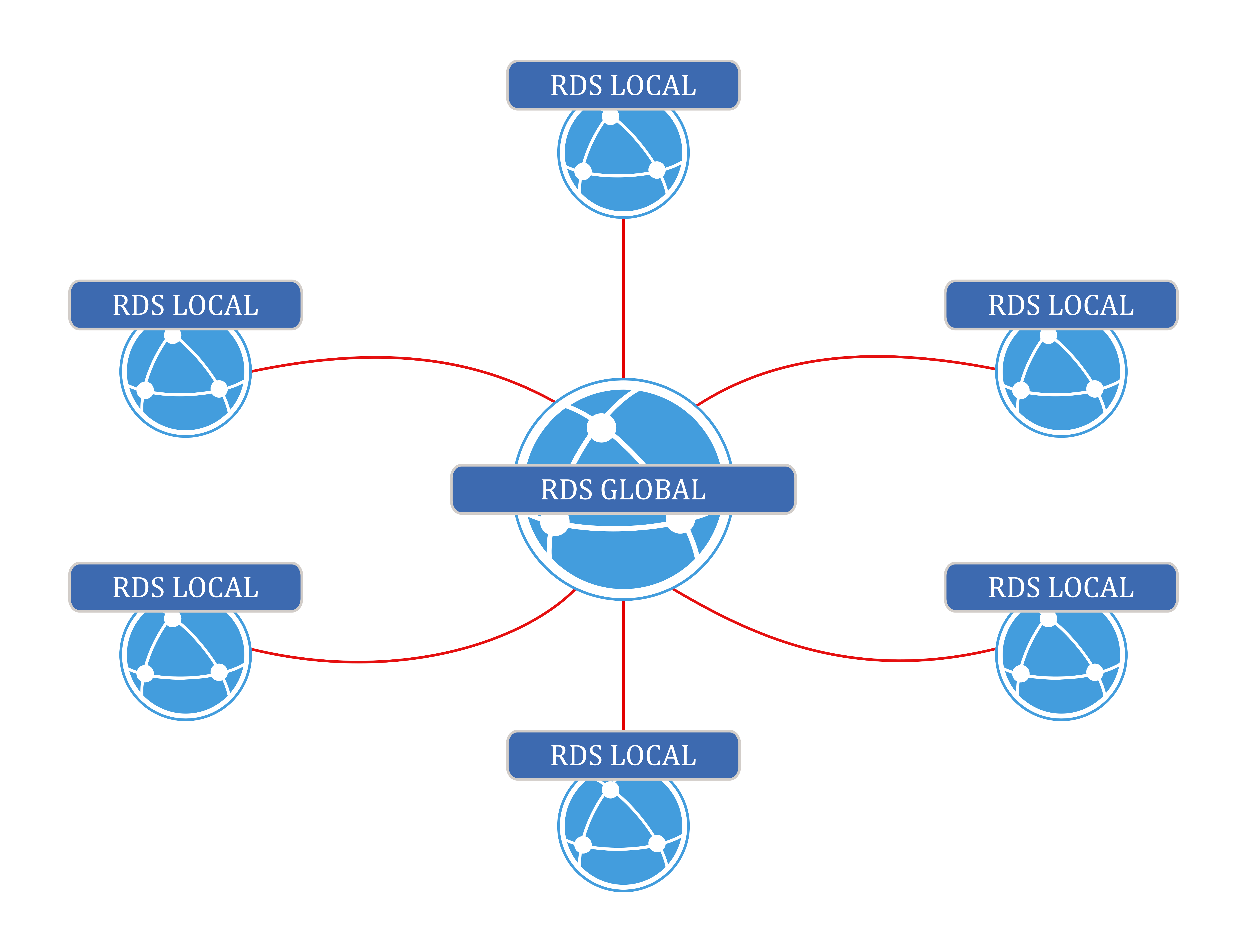
Hub and Spoke – Linked Data at work
The RDS-Global system provides the central repository for the canonical datasets. Participating organizations and projects may want to contribute data to that central system and, for that purpose, have their own RDS-Local systems connected to the central system, as depicted in the diagram below. A research group running their own RDS-Local instance may connect to the central repository and search for data through their own local system. The setup of a RDS-Local system is similar to the global one: the Lookup Service searches both the local database as well as the remote RDS-Global system via a REST connection based on the Reconciliation API.
Research data that is authored in an RDS-Local system can then be pushed to the central repository and made available to others as well. Each participating organization pushes data to its own named graph, thereby creating their very own dataset which – with some additional metadata such as a name and a logo – is also visible to other users of the same system.
Unified type system
Each of the datasets hosted by RDS uses its own vocabulary for entities. This means that a person is described using different types and properties in each of the datasets. To abstract from the many different vocabularies, RDS uses a unified type system. Each of the eight main supported entities – persons, artworks, groups, built works, places, digital documents, events and bibliographic entities – is described in an RDS-specific vocabulary based on CIDOC-CRM. Lookup results are translated from their original type into this representation. When generating descriptions as explained above, the used properties do not just depend on the type of the entity, but are also specific to the dataset.
RDS Use Cases
Unified access to all connected datasets
As mentioned above, the reference datasets hosted on RDS-Global are exposed to end users (e.g., researchers, professors, students, etc.) through an intuitive, Google-like search interface. The lookup and reconciliation services available in the platform deliver an abstraction layer over keyword indices. This returns a set of lookup candidates with identifier, label, type(s) and description which can be used for disambiguation.
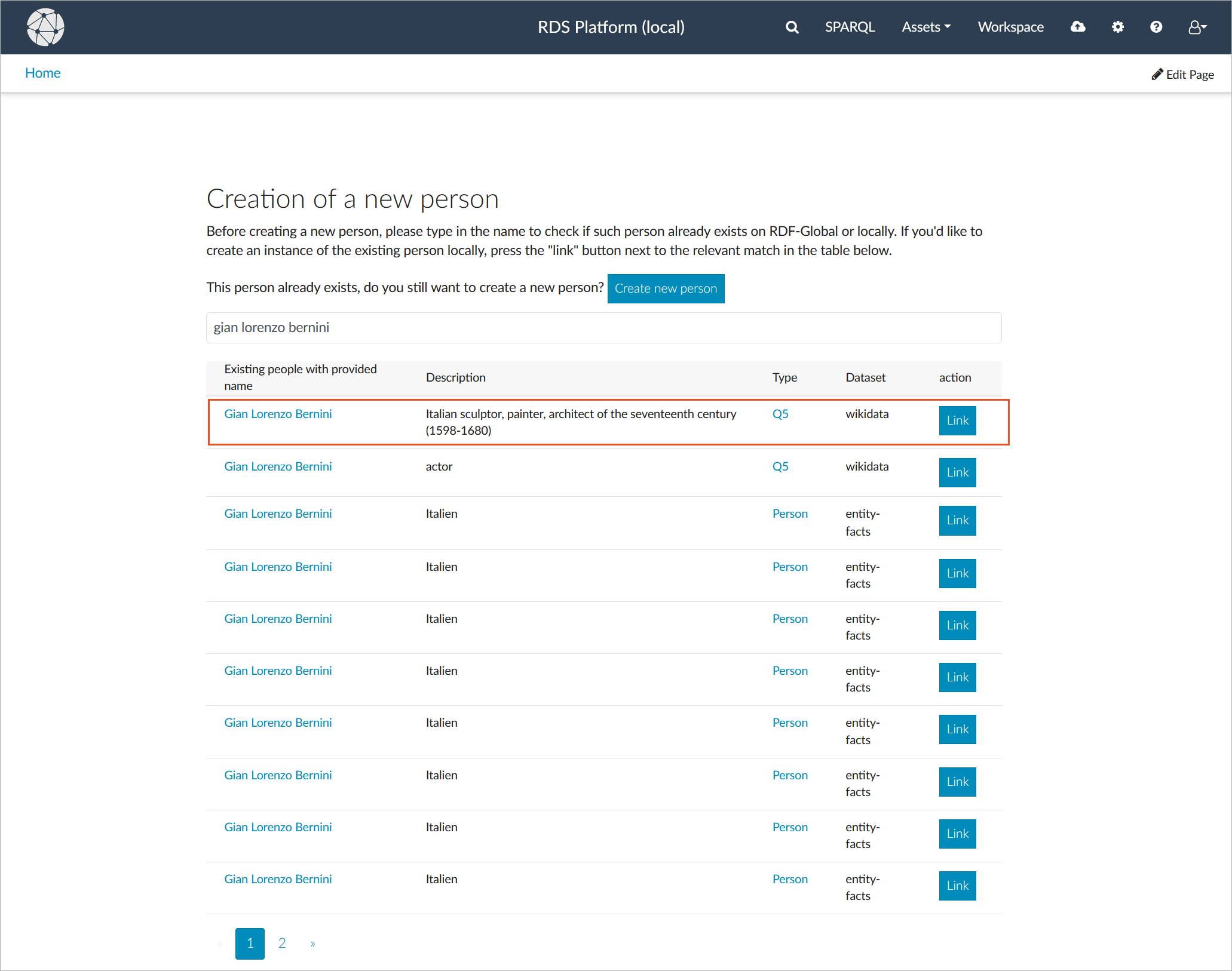
In the example below, we are searching for information on "Bernini". The description service (1) available in the platform provides a textual one-line summary of each resource, e.g., "Italian sculptor, painter, architect of the seventeenth century", and helps us identify the correct instance and distinguish Gian Lorenzo Bernini from Pietro Bernini (son and father). Descriptions can be fetched from a single property of a resource or composed of multiple properties using a template, allowing to combine multiple snippets of data into a concise summary.

Since the datasets in the RDS-Global system are interlinked, entries from multiple datasets that refer to the same entity can be grouped and shown as a combined result (2). As depicted in the screenshot above, each individual entry is shown with the respective type, dataset and description. In the case of Gian Lorenzo Bernini, we see that we have data available from three sources: GND, Deutsche Nationalbibliothek and Wikidata.
Authoring & publishing new data
As part of their research work, end users in the cultural heritage and humanities sector often collect and create vast amounts of data, which can include information about, e.g., books, maps, papers, images, pieces of art, architecture, etc., as well as any related metadata describing people (authors, creators, etc.), places, events, etc. The RDS service offered by SARI supports the creation of such data using predefined forms. This means that in their own RDS-Local systems, end users cannot only consume data from the upstream RDS-Global, but they can also create new data, or records. These records can be linked to existing entities from the users’ RDS-Local system or from RDS-Global, thus augmenting existing datasets and making data interoperable and reusable. This is achieved through a semantic forms component driven by the underlying semantic model / ontology.
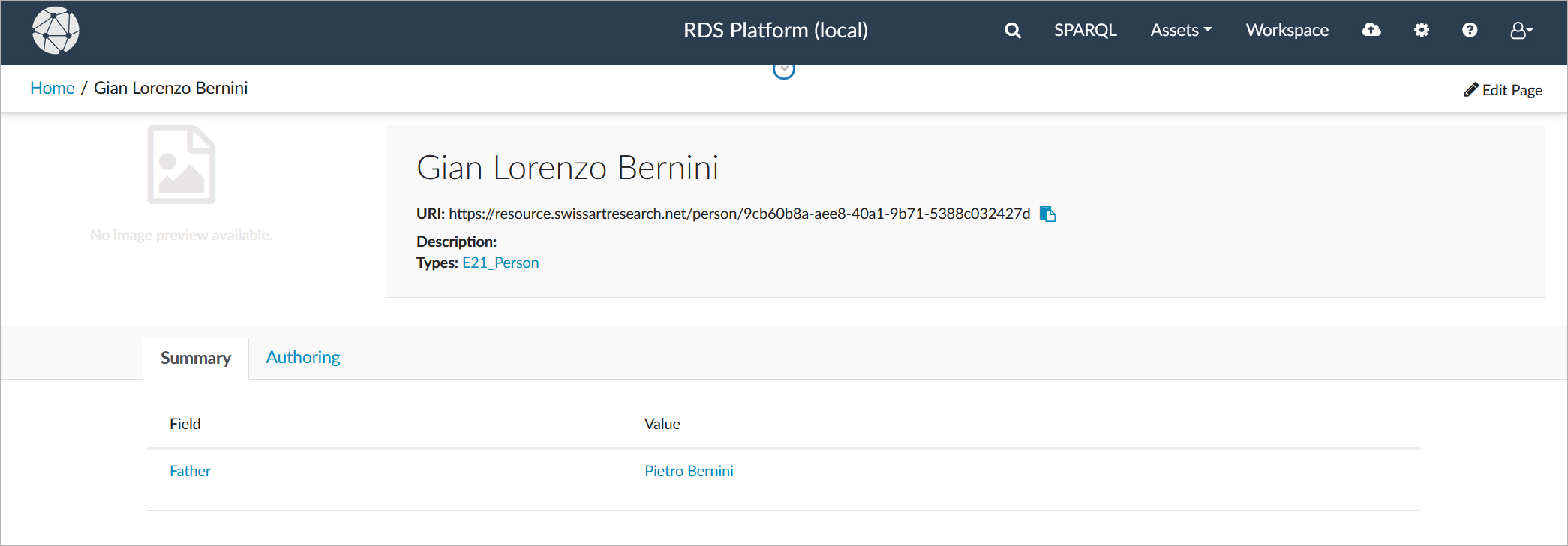
Let's go back to our Bernini example and say we want to create information about "Autumn in the Guise of Priapus", a marble sculpture which son and father Bernini worked on together, and therefore also need to augment the information available by adding this parent-child relationship. To do this, we go to our personal workspace, search for "Gian Lorenzo Bernini" and select the existing resource we want to augment with this relationship, as depicted in the screenshot below.
We can now use the form to create a new record - linking to the record of Gian Lorenzo Bernini on Wikidata - to capture the information about his father, and save it to our RDS-Local system.

Although we are linking our record to an existing resource in RDS-Global, our RDS-Local system records this as adding a new person. This new person stored in our local system will have a unique IRI that will be connected with the IRI of the person in the RDS-Global system through a "same as" relation, therefore preserving the provenance information that this is additional information provided by us.
New records can be subjected to an editorial workflow where reviewers can check newly created data, make or request changes, and approve records for publication. This ensures that the data created matches the quality standards established and is accurate.

Once new records are approved via the editorial workflow in an RDS-Local system, they can be published to RDS-Global via click of a button, enriching already existing information.
The shared records are then instantly available to other parties and projects and can be linked to from other entities. End users from other research departments or institutions can reuse this new data in their own research projects, build on it, extend it, and identify connections that were not visible in a single, local data source but only become apparent when combining information from multiple sources.
Data publication in RDS follows a number of access permissions and rules to ensure data governance, lineage and compliance. As such, all institutions contributing data to RDS-Global
- are only able to update or modify data that they have created and published;
- must clearly describe their datasets and include, e.g., provenance and license metadata; and
- must use an approval workflow within their institutions before publishing data to the central repository.
Integrating and reconciling existing research data
The described use cases so far focused on using RDS from the defined user interfaces, but much of the research data required in a project is already available today, often as structured data in formats other than RDF, e.g., CSV, JSON or XML. Extracting, transforming and loading such structured data is the first step in such a research project, and a key aspect of Linked Data publishing is that such new data should be properly reconciled with and linked to existing data, using RDS. Reconciliation refers to the creation of local identifiers and the resolution of identifiers from multiple sources. Identifiers can include names of places, persons, events, etc.
OpenRefine is a free, open source tool that allows for importing structured data from CSV, JSON or XML files and processing them using various transformations. One such transformation is the reconciliation of identifiers with external data sources based on some content, e.g., the name or the identifier of an entity. Through the use of metaphacts software, the RDS systems provide a so-called reconciliation endpoint based on the W3C Reconciliation API which can be addressed from OpenRefine.
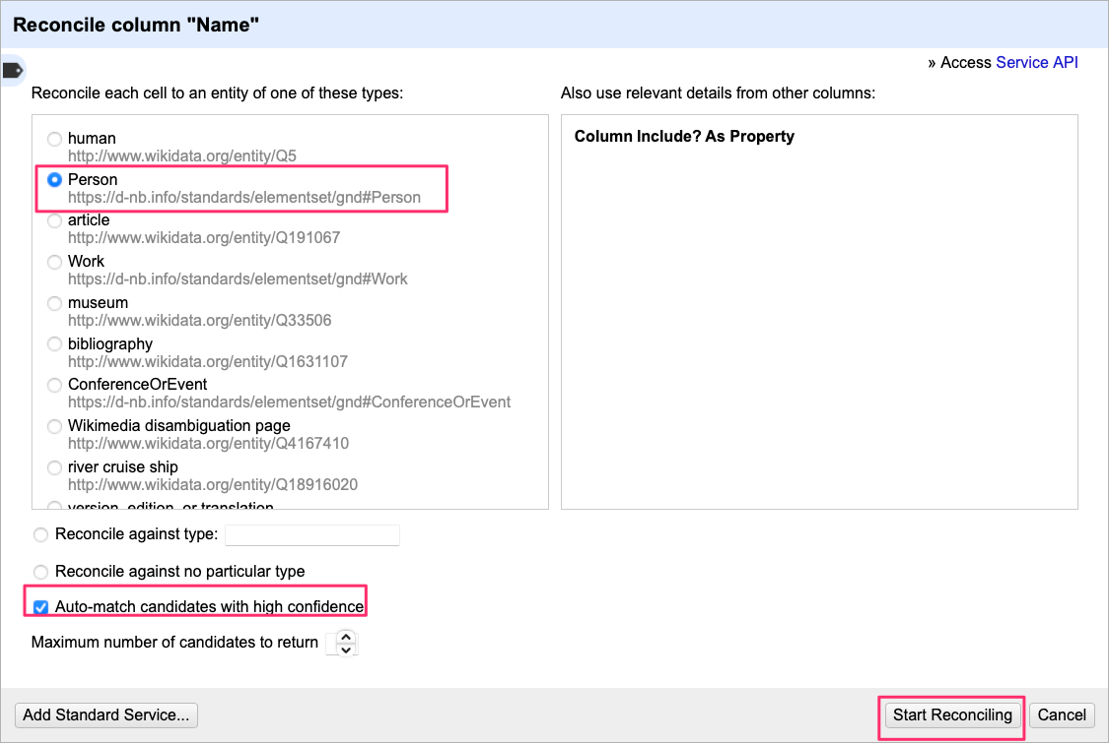
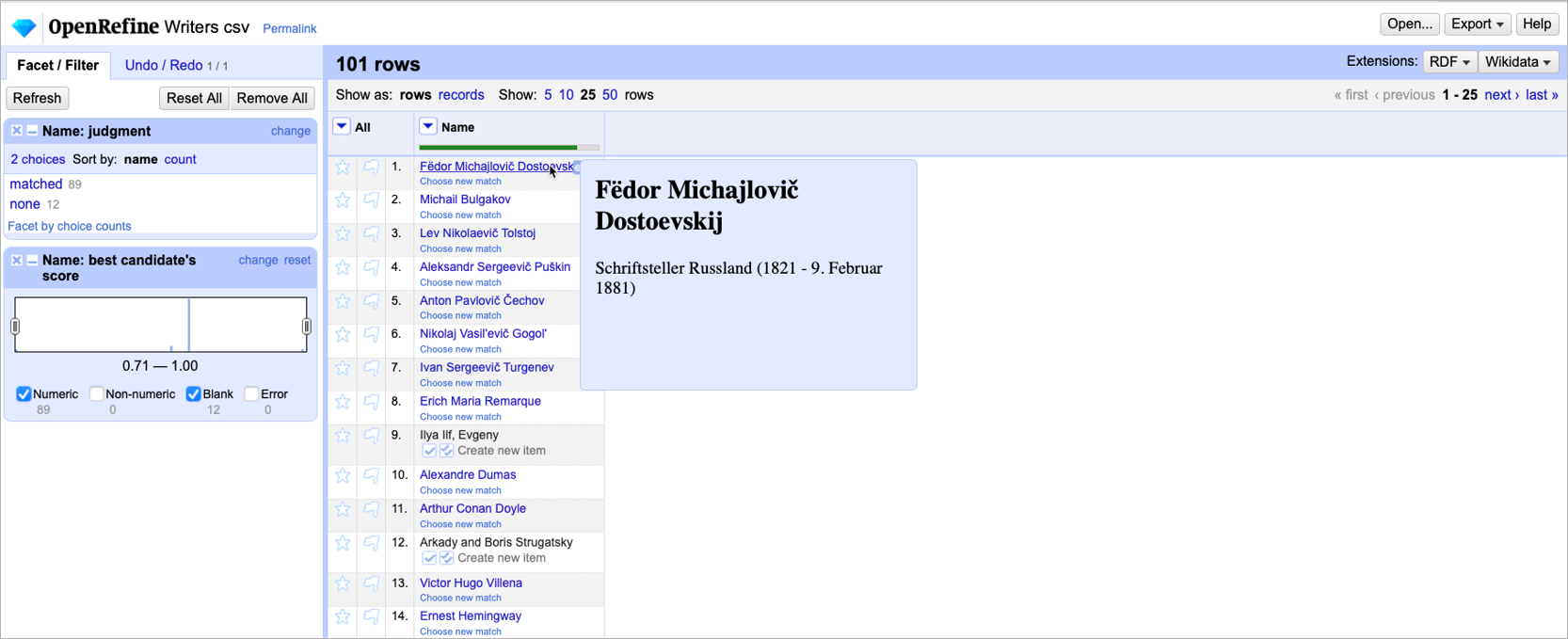
Because the W3C Reconciliation API is well-documented, other tools can easily be integrated in the same way, for example the TEI Publisher could be used with RDS as a service for entity markup.
This sounds great, where can I try it myself?
To interact with and explore the data published as part of the SARI RDS service, you can access the RDS-Global system here. If you want to try creating your own data and publishing it to the global system, you can set up an RDS-Local instance as described on GitHub (the required RDS client is available for free).
To learn more about metaphacts and our products, visit our website at www.metaphacts.com
Don't hesitate to reach out if you have any questions and make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.
References
[1] https://swissartresearch.net/


