At metaphacts we help customers leverage knowledge graphs to unlock the value of their data assets and drive digital transformation. We started out with this mission in 2014 and, since then, we've served a multitude of customers in pharma and life sciences, engineering and manufacturing, finance and insurance, as well as digital humanities and cultural heritage.
This blog post will give you an overview of what we have developed in customer projects over the years as our game plan to build a Knowledge Graph-driven, FAIR Data platform and drive digital transformation with data. The post will show you how our product metaphactory can support you every step of the way, and will highlight examples from the life sciences and pharma domains.
How does FAIR Data drive digital transformation?
So why is everyone talking about digital transformation? And - How does FAIR Data play into that and why is data so important?
Through our discussions with customers, we have been able to pinpoint three key benefits and expectations from digital transformation:
- Innovation enablement. This one is always at the top of the list, and we see considerable potential to enable new business, new products, and new ways of doing work when using the flexibility of digital tools and digital processes driven by the data that is already available to you.
- Improved operations. This can be achieved by utilizing data to build better integrated tools and to create a fully digital toolchain with no interruptions.
- Increased engagement. This is achieved through digital interfaces, either outward-facing - with customers, suppliers and partners - or internally - with your employees.
It might seem obvious, but the path to digital transformation should start by listening to people - customers and employees alike - to hear where the major gaps are. Transformation should be driven by data, meaning data-driven decisions, data-driven processes and data-driven tools.
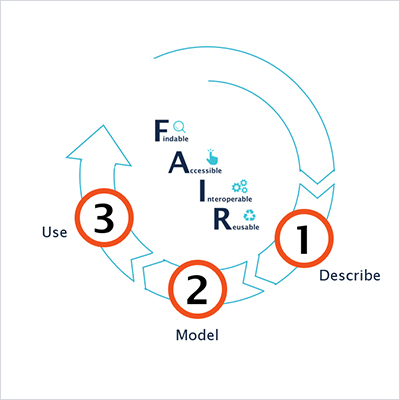
An agile approach that encourages experiments and allows you to go back to the planning board once you've collected experience and tested ideas is best suited for starting your digital transformation journey. In this agile cycle, data is the anchor and follows its own innovation cycle, where relevant datasets need to be described and modeled before they can be used. This is where the FAIR Data principles for Findable, Accessible, Interoperable and Reusable data come in, because following these principles will turn your data into your most valuable asset.

How FAIR Data can drive digital transformation and help you achieve your goals
The FAIR Data principles describe a total of 15 rules or guidelines which should enable you to make your data human and machine-actionable, but they lack detail on how to implement them. This is the gap that this blog post can hopefully close, by demonstrating how maintaining your data with a knowledge graph in metaphactory, can help you extract valuable knowledge that can be interpreted by machines or algorithms to drive prediction, for example with machine learning and artificial intelligence.
Building an agile, data-driven innovation cycle
As discussed earlier, data is key, but what we usually see in customer projects is that, today, data raises more questions than it can answer. This is usually not the case for the data created internally within one team, but it does apply to data that originated in a different team, a different department, or outside the organization. In the pharma industry, for example, customers often want to incorporate insights from clinical studies or pharmacokinetic and biospecimen data from other projects into their work. However, more often than not, they lack critical metadata for these assets:
- Who created this data?
- Which processing steps have been applied to this data?
- Whom could I reach out to if I need some of the raw base data which might not be included in what is available to me?
- Is this data reliable?
- Which process did it go through, and can we prove its correctness from other sources, or is there maybe even contradicting data available?
- What was the intended use for this data?
- Does it work for how I want to use it?
And the list can go on.
FAIR Data principles tackle exactly these requirements, which means that following them will help you provide the necessary metadata to answer these questions in your organization and for your projects.
Step 1: Describe your datasets with a data catalog
So how do we create the relevant metadata? The proposed process is applicable to all of your own data - your private and proprietary data - but also to public data. In the pharma and life sciences domains, these public data sources may include DrugBank, ChEMBL, PubMed, PDB, etc. We advocate for running all of this data through one and the same documentation process to store relevant metadata, including provenance and lineage information. This might initially be an independent or even a manual step but, over time, it needs to be integrated into your toolchain so this metadata gets generated along the way.
Our approach uses an open data standard called RDF, which is a W3C standard, and the foundation for making data FAIR. There are a number of standardized models to describe data and we highly recommend using DCAT to describe your datasets, their source, distribution, and classification. For provenance and lineage information, we recommend using PROV-O; this will allow you store metadata on how the data was processed, transformed, modified, or adjusted in any other way.
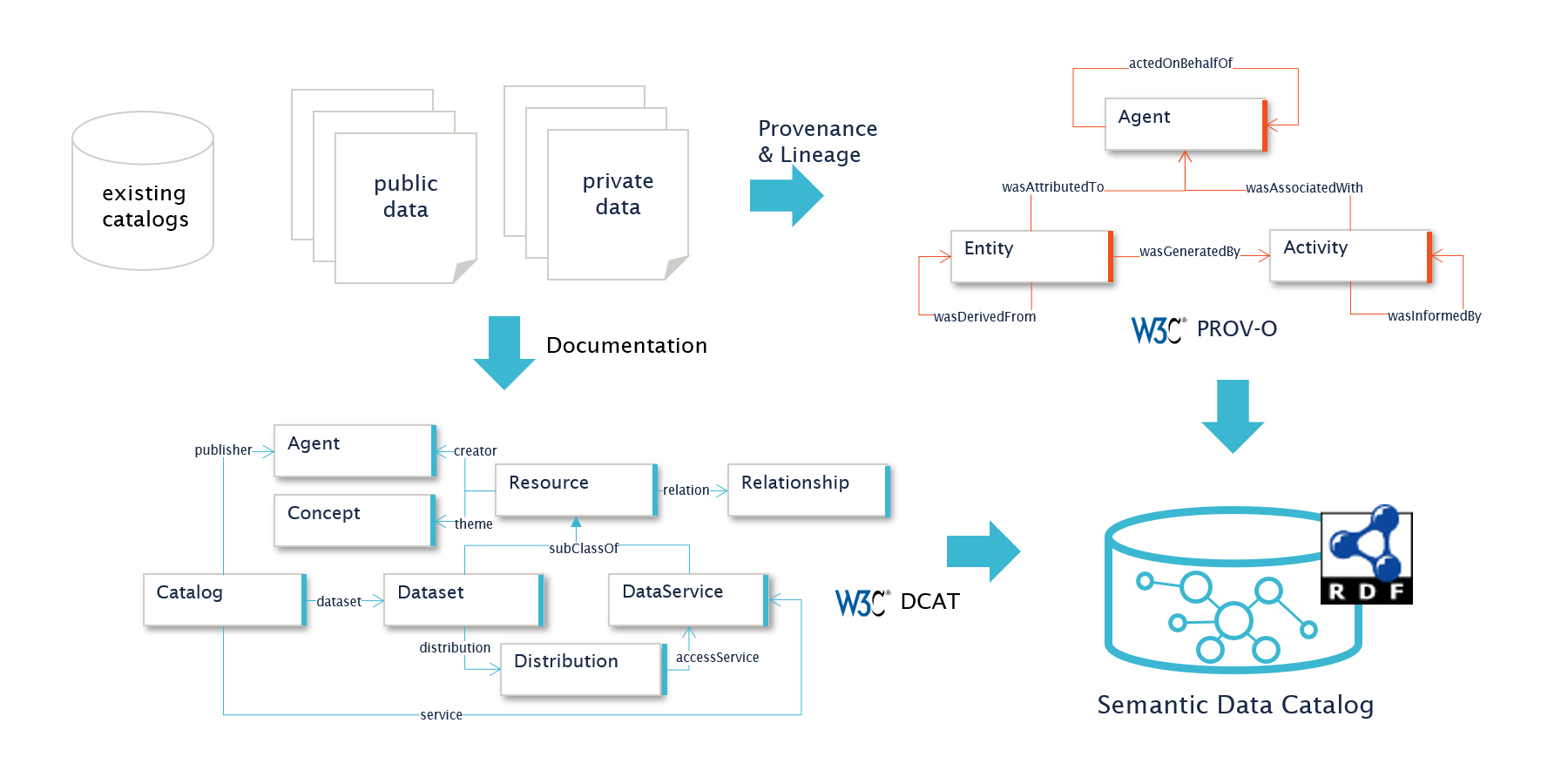
Use a standard data model, such as RDF; Use DCAT to describe your datasets and PROV-O to store provenance information
From this metadata you can take the next step towards FAIR Data, by building your semantic data catalog. Most companies already have a data cataloging solution which could simply be augmented, but we see more and more customers move to a semantic data catalog based on open standards, and away from proprietary solutions.
This might even be a catalog of catalogs, where many internal, often proprietary catalog solutions can be combined into one large semantic catalog, which uses an open standard data format (RDF). Customers implement this with our platform metaphactory to provide one consistent view, with one vocabulary and (metadata-)model to span all data sources, and one query interface for users to find the datasets they are looking for.
One important aspect here is that there is no need to catalog all your data before you can start on the next steps. We in fact recommend choosing two or three relevant data sources which can support one of your use cases, and getting started with that. And this should be an iterative approach which allows you to go back to this step at any point in time to add in more data sources which you describe in your semantic data catalog.
Step 2: Model the meaning of your data
With the next step, the data catalog is integrated into an overarching model. This goes beyond a simple database schema and refers to a semantic model - or ontology - that describes the core concepts and relations in your domain and your daily work, as well as relevant attributes per concept.
Here, too, we propose using two W3C standards - OWL and SHACL. OWL provides the relevant expressiveness to model your ontology, while SHACL allows you to define constraints on this ontology, for example, to define that one gene can either encode none, one or many proteins.
This modeling step is unique to the Knowledge Graph, as only knowledge graphs support semantic modeling and allow you to focus on meaning and knowledge, compared to just describing data structures.

Data catalog and controlled vocabularies mapping into an example ontology from the life sciences domain
It is often described as an overwhelming task to build an ontology, as you will need a lot of domain specific knowledge as well as semantic modelling skills, but with metaphactory we have established an approach which, in many cases, will only require domain knowledge to succeed and will abstract the complexity of semantic modeling behind a visual ontology editor. To further accelerate the process, we recommend to follow an agile approach of modeling only the parts which you need and incrementally grow your ontology with new use cases, new datasets, new information needs, or changed understanding of your data.
Ontology best practices
There are also a lot of relevant domain models already publicly available and many of the publicly available RDF datasets come with their own partial ontology for the provided data. This is important, because it is very common to integrate data from various sources. We, therefore, recommend maintaining an overarching ontology with really just the absolute core concepts, relations and attributes, but integrating all relevant domains. In some cases this is driven by an open standard ontology (e.g., ISO) or it is just your own abstracted overarching and integrating model. The lower-level ontologies then model specific datasets or sub-domains in more detail and tie into the overarching ontology. This provides modularity and separation of concerns, and simplifies work for the teams involved.
This approach helps you to involve your domain experts, support them in working together with the semantic modelers on the individual ontologies, and provide feedback based on their unique domain knowledge.
The use of SHACL also enables automated validation of data and metadata, to ensure data quality.
Integrating controlled vocabularies
Another key step in modelling and classifying your data is the tie-in to standard vocabularies. These vocabularies usually exist within the team, group or company, but they are often not well documented or interlinked, or individual groups use slightly different vocabularies. Additionally, publicly available data might not match directly into the internal vocabulary.
We recommend using the W3C SKOS standard to build your vocabularies and to classify your data with them. This will help people to find relevant data and better understand where certain datasets might be applicable.
Unique IDs
To make all of this possible with data from various sources, it is very important to have unique IDs for your data, your ontologies and vocabularies. The RDF standard has namespaces and IDs (called IRIs) as a built-in structure with every entity you store, and we recommend using generated IDs (seemingly random UUIDs with guaranteed uniqueness) for your own data, ontologies and vocabularies, and basing these IDs on your own namespace. The reason for this is that these IDs represent the actual "thing", for example a specific gene. Do not fall into the trap of building IDs from names, since 1) RDF provides you with labels, incl. multilinguality, and 2) names might change (like when the Human Gene SEPT1 was renamed to SEPTIN1 to avoid it being interpreted as a date) and an ID based on the name might not be accurate anymore after such a change. Using generated IDs helps you avoid such situations and therefore ensures that all "things" are always referenced correctly with a globally unique and never changing ID, while names can be adjusted as needed.
For publicly available or other kinds of external data, we recommend keeping existing IDs. Namespace them with their source (assuming it is not yet RDF), and finally include the mapping of IDs into your data, ontologies or vocabularies.
Entity reconciliation
A common question which arises during the first few iterations is "How do I maintain the information on which internal IDs resolve to which of these new generated IRI IDs? And how can I know if I have already generated an ID for a certain entity?"
We recommend using the W3C reconciliation service API (which is not yet a standard, but in draft status), through which the knowledge graph can be queried for matching entities and their IDs. The alternative - persisting all foreign ID mappings to their IRIs in some kind of entity naming service - will just not scale.
Step 3: Use your data and build the user experience
With your data described and modelled, there is one final step to really derive value from it - building the user experience, or what could also be referred to as mapping the user journey for interacting with this data.
The most successful approach we have seen is to start with simple wireframes and highlight the types of interactions your users require. For example: search, exploration and visualizations, or collaboration and sharing of data between users and groups. This can then be turned into an actual user interface with the metaphactory low-code platform. We have seen customers build many different things using our low-code platform - from smaller, independent applications for a specific use case, to generic, company-wide data hubs or FAIR Data platforms.
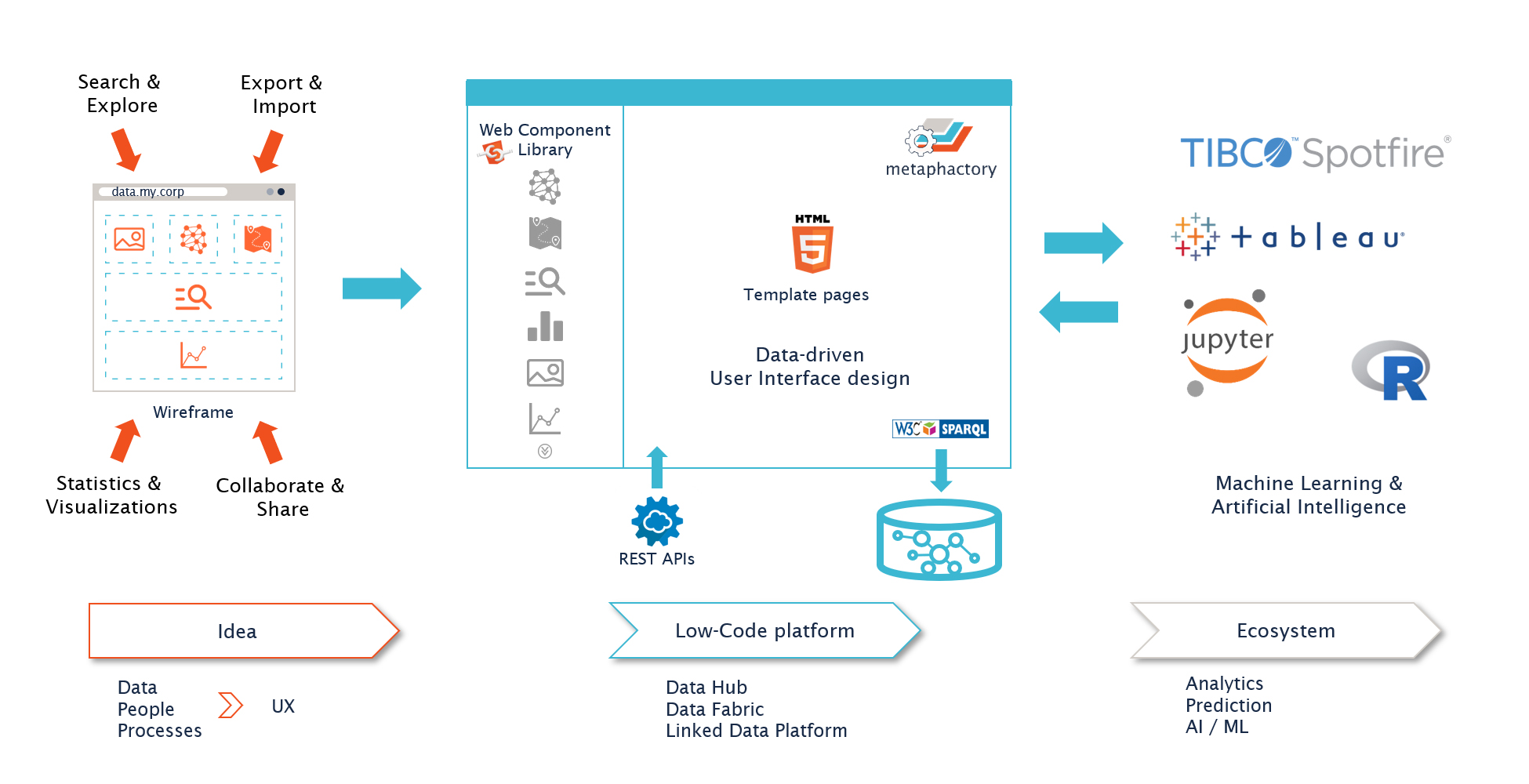
Use a low-code platform - metaphactory - to build the user experience
The reason we recommend a low-code platform is that we see little value in writing your own frontend components. A low-code platform takes most of the work away from you. metaphactory can derive the interface design and configuration directly from your ontology, like configuration of forms to modify or enter data, search interfaces including filters and facets, and many more aspects of a modern user experience. This means you can focus on defining the interaction patterns for your data, select the right components to best visualize what is important, and minimize the effort in building and maintaining these user interfaces.
This approach enables rapid prototyping and makes it possible to get from idea to production in as little as one week.
Since no application lives on its own and interaction with existing tools, like common analytics or AI/ML platforms, is required, the knowledge graph allows you to easily share data between these tools. Analytics tools like Tableau or Spotfire benefit from the knowledge graph because the relations between data points and the explicit semantic model allow a data scientist to quickly select the correct datasets, combine the data they use today with other relevant data, or exclude data based on available metadata information.
Machine learning tools and algorithms, on the other hand, can be trained using the knowledge graph, i.e. they can be fed with machine-interpretable, semantically-modeled and described data, instead of just large amounts of raw data. Resulting predictions can be stored back into the knowledge graph to further extend the available knowledge.
Agile iterations for all Knowledge Graph assets
I have highlighted the importance of agility several times throughout this blog post. In the world of knowledge graphs, this is something you can apply at every step of the way, from describing the datasets in your catalog, through mapping the data into your ontology and classifying the data with your vocabularies, to building UI templates for establishing the user interface and allowing users to interact with that data.
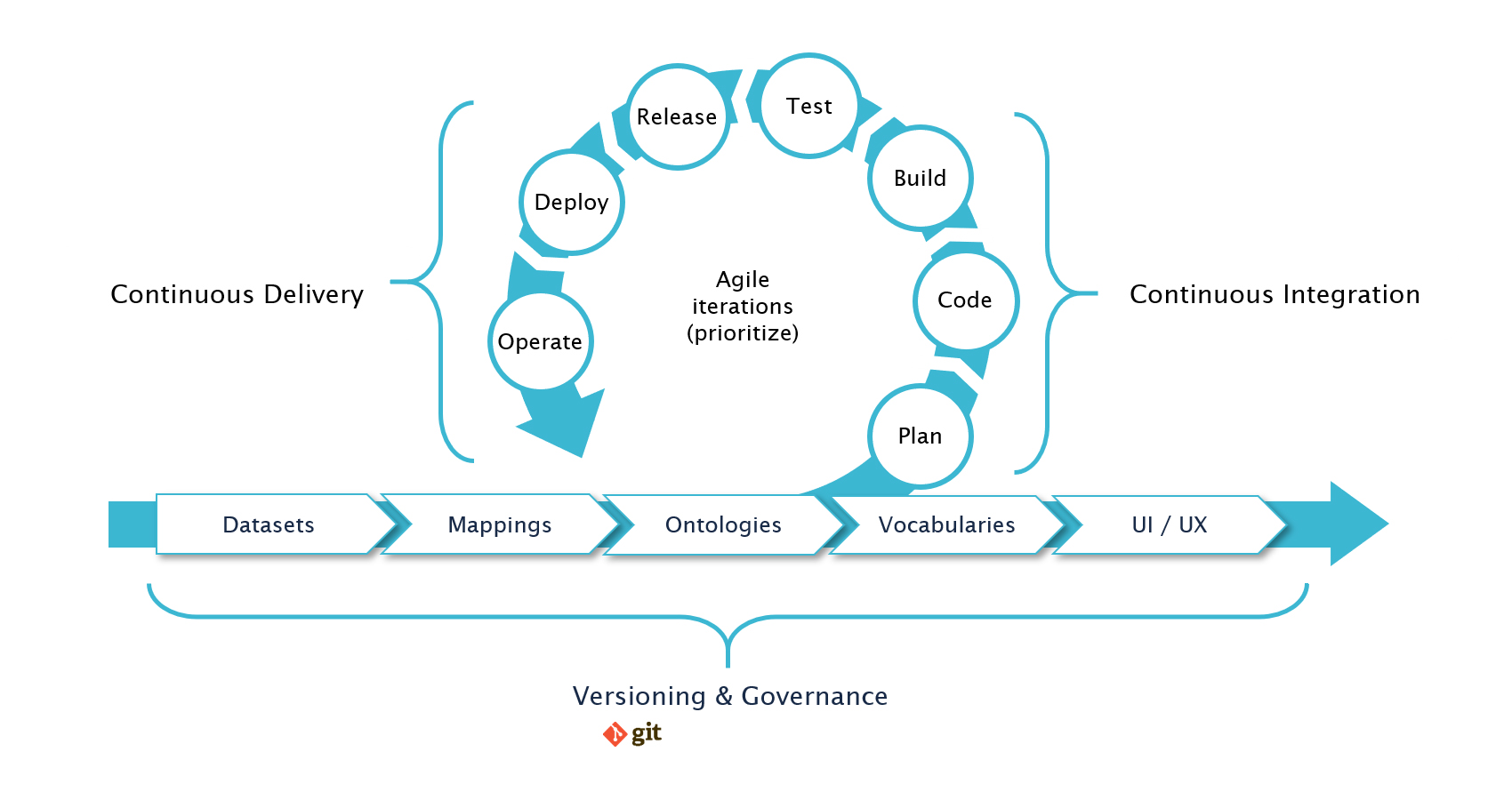
Agile iterations for all Knowledge Graph assets
The agile process allows for the continuous integration of changes and the continuous delivery of these changes into production. With our customers, we build on versioning systems like git for versioning assets, and on data-driven workflows to additionally enable the necessary governance required in an enterprise context.
This works out best as an integrated process, where really everything from describing the datasets, through mapping data and defining ontologies and vocabularies, to building user interfaces follows the agile iteration cycle and connects into the same central versioning system and governance workflows. This helps set up a consistent practice for building and maintaining these key knowledge graph assets.
Get started with your Knowledge Graph-driven FAIR Data platform today!
Sounds cool? You can get started with your Knowledge Graph-driven FAIR Data platform today. And, of course, don’t hesitate to get in touch with us if you have any questions.
Make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.

