
Finding paths in a graph is a well defined space in mathematics and computer science. The Seven Bridges of Königsberg problem from 1736 - which asked to devise a roundtrip through the city of Königsberg in Prussia while crossing each bridge in the city only once - is one of the most famous real world problems and resulted in the foundations of today's graph theory.
While the term pathfinding might often be associated with finding the shortest path (for example, in a geographical context or in computer networks), the seven bridges problem is a good example showing that the shortest path is not necessarily the optimal or desired path for a given problem or information need.
Although they are graph databases, semantic graph databases lacked native support for pathfinding algorithms for a time (with a few exceptions). This was initially mainly due to the slightly different focus on data integration and a very expressive and standardized query language, SPARQL. SPARQL itself is a graph pattern matching language, which may naturally come with some trade-offs (e.g., in terms of index design, query optimization and computing cost) when applied to other use cases such as pathfinding.
With matured technology, evolution of standards and increased availability of computing resources, nowadays, most RDF databases natively support pathfinding algorithms. Most recently, our partner Ontotext released GraphDB 9.9 featuring sophisticated pathfinding algorithms which are fully compliant with and accessible through standard SPARQL 1.1 service extensions. See [1] and [2].
Following our mission, we have taken up the challenge to enable business users and domain experts to utilize this functionality without having knowledge about SPARQL or the particulars of pathfinding algorithms. When designing metaphactory's new visual pathfinding interface - released just last week with metaphactory 4.3, we focused on two primary usage scenarios:
Investigative Knowledge Graph Exploration
For this use case, we start with the assumption that end users (data scientists, subject matter experts like biologists, researchers, product technicians, etc.) can precisely name and identify the start and end nodes of interest, e.g., using keyword search and semantic disambiguation. However, they do not know what the possible relation(s) between the two nodes is/are, or if there are any at all.
As the data schema, the data partitioning and the details of the data itself are more or less unknown to the end user, metaphactory's new visual pathfinding feature aims at enabling these users to explore and refine the graph path space interactively, without requiring any prior knowledge of the underlying graph structure.
One good example is Wikidata. Let's imagine that our user wants to use Wikidata to explore how "Alzheimer's" (the disease) is related to "Dopamine" (a chemical compound from the group of neurotransmitters). Even for knowledge graph experts with advanced knowledge of SPARQL, performing such a query in standard SPARQL would require a lot of time and effort, incl. inspecting the Wikidata ontology, writing union queries with wildcard predicates, inspecting results, iterating and refining.
Using metaphactory's pathfinding interface, end users themselves can visually define a start and an end node (in this case "Alzheimer's" and "Dopamine" respectively), as we can see in the screenshot below. They can interactively explore the result set with the relations between these two nodes and refine the search parameters to uncover the most meaningful paths (e.g., by defining the number of relations to be traversed or the relations which should be excluded because they do not yield any meaningful results).
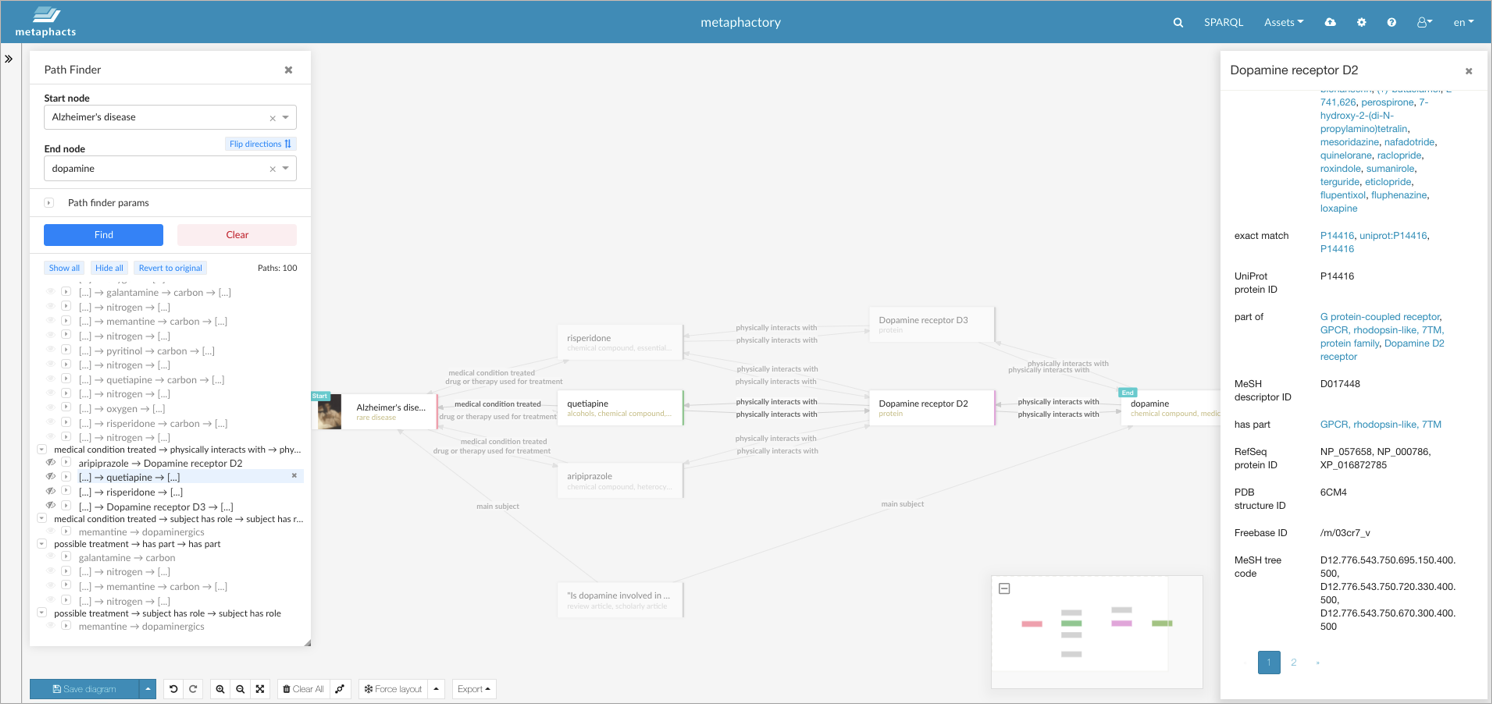
You can try metaphactory's pathfinding interface on your own using our public Wikidata demo system. Please keep in mind that Wikidata is big and diverse, so the graph has very different characteristics depending on the area you are looking at. For example, in life science, the nodes like proteins, genes or compounds are well connected, i.e. the graph is very dense and pathfinding algorithms return results quickly. However, in other areas, the graph might be more sparse and, as such, the underlying algorithms may take longer to complete within the given limits. A general good practice is to start small; for example, you can define min and max path lengths that are low and close to each other and also limit the maximum number of paths. If this returns quickly, you can iteratively increase the limits and fine-tune, for example, edges to exclude.
Targeted Problem Solving
Here we start with an information need and a business problem that is well-known to the application engineer who needs to configure the Pathfinder panel and define the backend configuration to target this particular use case. This may include deciding what kind of graph algorithm to use (shortest path, all paths) and whether it should be limited to particular relations or node types only.
Schaeffler, a global automotive and industrial supplier, is using metaphactory to implement a knowledge graph-based data catalog. The use case is mainly focused on data democratization, i.e. enabling end users to transparently find and access distributed data sources across data silos in a connected enterprise. Based on semantic metadata, end users are enabled, for example, to find relevant tables and attributes (columns) within the data lake. However, the data is often scattered in various relational tables and accessing this data for analytical purposes requires joining an unknown number of tables. This means that data scientists are typically faced with the challenge of finding a relevant join path between relational tables within the data lake. Relevant does not necessarily mean minimizing the number of tables to join, but possibly includes other aspects like join cardinalities, access restrictions or simply retrieving the data in context, i.e. projecting data from intermediate tables as well.
As the metadata of the data lake is multifaceted and there are various kinds of relations and nodes in the underlying metadata graph, metaphactory's pathfinding feature has been tailored to target this particular business problem. That is, the pathfinding service in the backend has been pre-configured to only traverse nodes of type table and associatedTo relations (which is an abstract relation over various kinds of relations like primary, foreign key relations). In addition, the graphical interface has been customized utilizing custom node and edge style configurations (e.g., cardinalities on edges). In the scenario below, the user may want, for example, to retrieve specific packaging information for each material and purchasing organization. The Pathfinder panel retrieves and visualizes three possible solution paths from the backend. The ability to see and explore them interactively provides necessary context to the data scientist. For example, he may now conclude that the join via the "Production Versions of Material" table should be considered, as possibly different production versions of material may have different packaging instructions per purchasing customer.
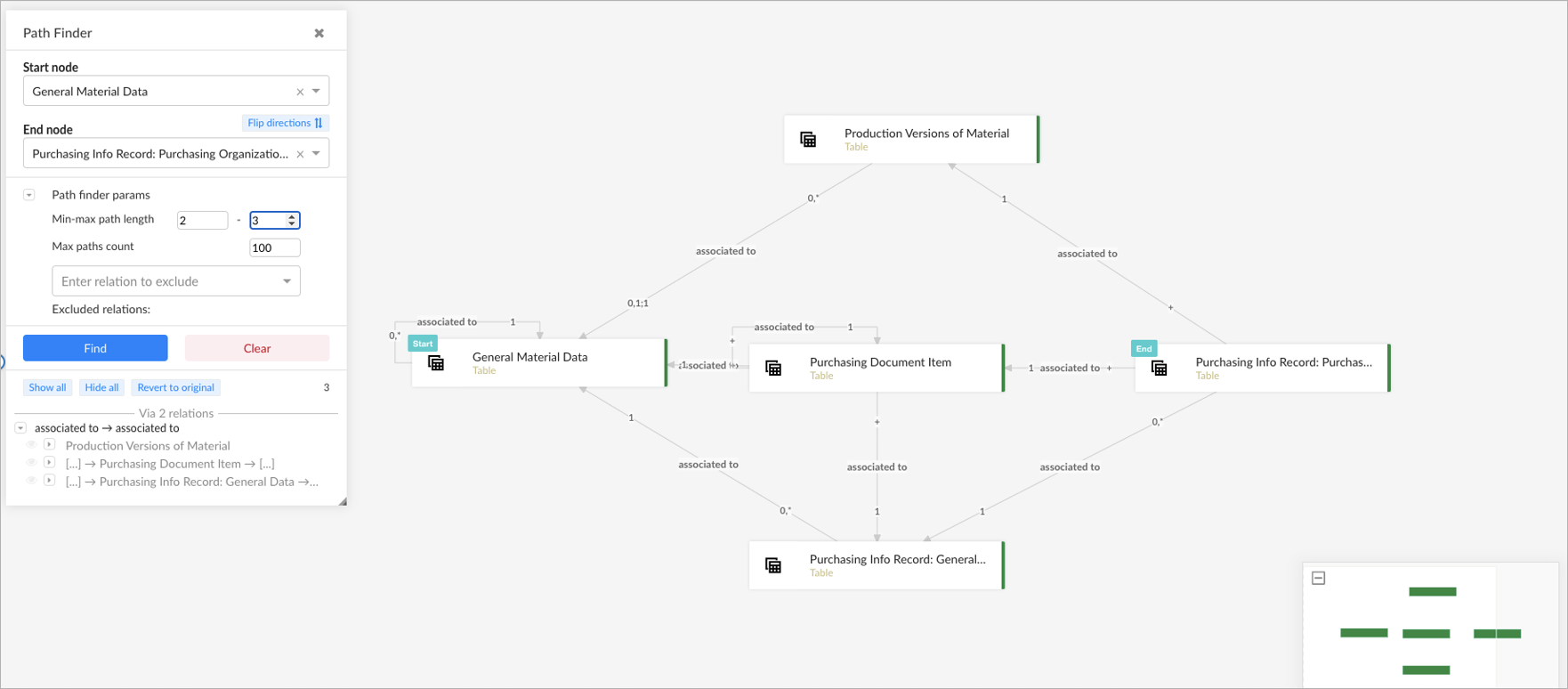
With the metaphactory 4.3 release, we support application engineers in implementing such use cases by providing great customization flexibility to tailor the pathfinding configuration to use-case specific needs. On the one hand, the Pathfinder component can be flexibly combined with existing graph visualizations (e.g., use-case specific node styles) and interaction patterns.
metaphactory 4.3 integrates out-of-the-box with a number of pathfinding implementations from different database vendors like GraphDB and Stardog. Through its built-in federation service, metaphactory allows for encapsulating the pathfinding functionality, while hiding database vendor specific implementation details. This enables, for example, seamless access to Stardog's path queries, which are based on a proprietary extension of SPARQL and would otherwise be difficult to process by standard libraries and visualization components. In addition, the pathfinding service abstraction simplifies a global configuration of the pathfinding algorithms, i.e. relations and nodes can be included or excluded in a single and central configuration. For example, on Wikidata, we configured the pathfinding service globally to traverse direct properties only and to exclude property statements.
Finally, metaphactory provides a simple, but generic fallback pathfinding service implementation for databases which do not yet natively support pathfinding. Naturally, this implementation is limited in performance; however, it can satisfy use cases with a path length of up to six relations.
This sounds cool! How can I try it myself?
You can try and tweak the first example described in this blog post using our public Wikidata demo system. To try the new pathfinding interface with your own data, you can get started with metaphactory today using our 14-day free trial. And, of course, don't hesitate to reach out if you want to learn more about how this feature can be leveraged for your use case.
Make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.

