
The SPARQL default graph is a concept that can confuse even frequent SPARQL users. In this article, we will go over what the default graph actually is, why it seems to be something different in every RDF database, and how you can come to grips with those differences and query with confidence.
We will also address the most common challenges and misconceptions, providing practical guidance on how to navigate these differences, along with insights into how metaphactory tackles these issues. Whether you're working with a single dataset or querying across multiple sources, developing a strong understanding of the default graph will enable you to query with both precision and confidence. Keep reading to learn more!
Demystifying the default graph
Let’s say we have two RDF files. In the first file, using Turtle syntax, we have some information about Bob:
@prefix ex: <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
ex:bob a foaf:Person ;
foaf:name "Bob" .
In the second file, using TriG syntax, we have some information about Alice and Martha:
@prefix ex: <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
ex:graph1 {
ex:alice a foaf:Person ;
foaf:name "Alice" ;
}
ex:graph2 {
ex:martha a foaf:Person ;
foaf:name "Martha" ;
}
Note that in this second file, some named graph information is incorporated: the data about Alice is in a named graph ex:graph1, and the data about Martha is in ex:graph2. This will become important later on. First, we use an Eclipse RDF4J Server to load these two files into a database, and then we do a SPARQL query to find out which people exist in the database:
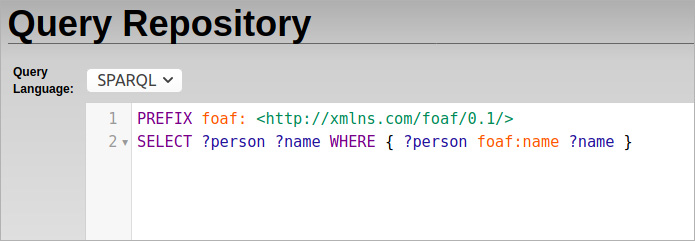
The result:
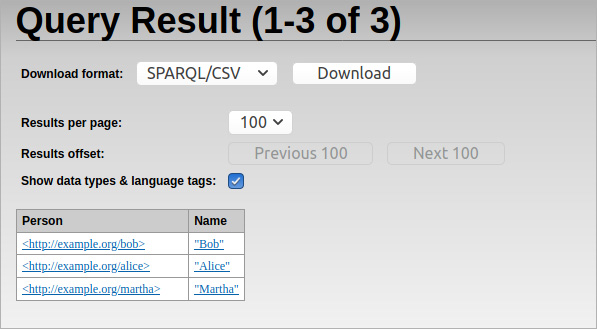
Next, we try the very same thing on an Apache Jena Fuseki server. The result:
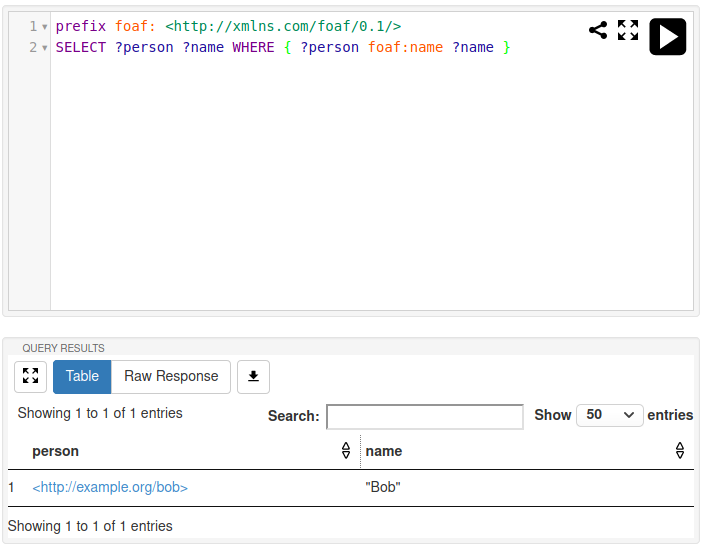
On both systems, we are doing the exact same query, on the exact same input files. Jena reports there is one query result, RDF4J reports three. Surely there must be a bug somewhere here - who is correct?
The somewhat counter-intuitive answer is that both are correct. To understand why this is the case, we will need to go over some basic terminology first.
Datasets
In SPARQL, all queries and updates operate over an RDF dataset. A dataset is a collection of RDF graphs: exactly one default graph (which is unnamed) and zero or more named graphs. The name of a named graph is an IRI, which can be used to identify the graph in queries and updates.
In a SPARQL query, all basic statement patterns are always matched against the default graph in the dataset, except when a GRAPH clause is involved. So:
SELECT ?person ?name
WHERE { ?person foaf:name ?name }
always retrieves all people and their names from the default graph. However, the following query:
SELECT ?person ?name
WHERE { GRAPH ex:graph1 {?person foaf:name ?name } }
retrieves all people and their name from the ex:graph1 named graph (if that graph is part of the dataset). Finally, the following:
SELECT ?person ?name
WHERE { GRAPH ?g {?person foaf:name ?name } }
retrieves all people and their names from all named graphs in the dataset (but not the default graph).
So far, this is all very straightforward. However, how do we define what the dataset is, and which named graphs are in that dataset? That question is at the heart of the difference between Jena’s and RDF4J’s answer to the same query, and we will now explore why that is.
Inclusive and exclusive datasets
In the SPARQL queries shown up to now, the dataset is left implicit: we are not saying anything in the query itself about what should be included in the dataset. When we do this query:
SELECT ?person ?name
WHERE { ?person foaf:name ?name }
We are merely saying "give me the data in whatever you consider the default graph" , and when we do this query:
SELECT ?person ?name
WHERE { GRAPH ex:graph1 {?person foaf:name ?name } }
We are merely saying "give me all information in the named graph ex:graph1 if that named graph is in your dataset."
So when we send either query to a SPARQL endpoint, it is up to that SPARQL endpoint to determine what the dataset actually looks like. It is at this point that the differences in behavior between various triplestores creep in. There are, roughly speaking, two main approaches: one camp uses an inclusive dataset, and the other side uses an exclusive dataset definition.
Triplestores that use an inclusive dataset definition operate on the assumption that if a user hasn’t said anything specific about which particular graph(s) they want to query, they essentially want to query everything in the database.
When the implicit dataset is inclusive, all data in the store is considered part of the default graph of that implicit dataset. This is the mode in which an RDF4J Server operates by default: the data from all graphs is implicitly considered part of the default graph, so the query returns data from all graphs (even if the query does not use any GRAPH clauses). So this is why, when we queried RDF4J for all persons earlier, we got back not just Bob, but also Alice and Martha.
Implementations that use an exclusive dataset definition operate on the assumption that the implicit dataset should reflect 1:1 how data has been added to the database: statements that have been added without a specific named graph are part of the default graph, but statements that have been added into a specific named graph are not part of the default graph. This is the mode in which, as we have seen, Fuseki operates by default: only the data that has no specific named graph information is implicitly considered part of the default graph, so the query only returns Bob, not Alice or Martha. (As an aside: I should point out that both Eclipse RDF4J and Apache Jena offer options to change their default behavior.)
So, what do you do if you want to ask questions of a SPARQL endpoint where you don’t know exactly how it defines the implicit dataset? We need some way to make it explicit what we want the dataset to be when we send our query.
Making the dataset explicit
The SPARQL query language has a mechanism for making the dataset explicit: the FROM and FROM NAMED clauses. These clauses can be added to any SPARQL query and together define exactly what the dataset for that particular query looks like, regardless of how the triplestore defines its implicit dataset.
The FROM clause defines what named graphs are part of the default graph (you can add more than one graph to the default graph by simply having multiple FROM clauses). So if we want to make it explicit that only the graphs ex:graph1 and ex:graph2 from our second file should be part of our query’s dataset, we can indicate that in our query as follows:
SELECT ?person ?name
FROM ex:graph1
FROM ex:graph2
WHERE { ?person foaf:name ?name }
The result of this query will be:
| person | name |
|---|---|
| ex:alice | "Alice" |
| ex:martha | "Martha" |
Because the query now explicitly defines its dataset, we can be sure that any triplestore will only give this result, regardless of how it defines its implicit dataset. (I should perhaps clarify one thing at this point: a FROM clause is not an instruction to the SPARQL endpoint to go and find the named graph somewhere on the Web and load it. Some SPARQL endpoints may choose to do this, but most RDF databases will simply look at what they already have stored in their database, and match with that.)
In contrast to FROM, which defines the default graph of our dataset, the FROM NAMED clause defines what graphs are included in our dataset as named graphs. As with FROM, you can have multiple FROM NAMED clauses in any SPARQL query to add more than one named graph, and we can of course combine FROM and FROM NAMED clauses. So:
SELECT ?person ?name
FROM ex:graph2
FROM NAMED ex:graph1
WHERE { ?person foaf:name ?name }
will always return:
| person | name |
|---|---|
| ex:martha | "Martha" |
It is worth looking at this example in a bit more detail. Our dataset definition consists of two parts: the first line (FROM ex:graph2) expresses that ex:graph2 is considered the default graph for this query. The second line (FROM NAMED ex:graph1) expresses that ex:graph1 is also part of the dataset, but not as part of the default graph, only as a named graph.
The next bit of the query (our WHERE clause) then only queries the default graph (because there is no GRAPH clause used anywhere), so the result will only contain data from the default graph: ex:graph2.
If we want the information from ex:graph1 back with this dataset definition, we need to introduce a GRAPH clause, and expand our graph pattern to get data from both the default graph and the named graph:
SELECT ?person ?name
FROM ex:graph2
FROM NAMED ex:graph1
WHERE {
{ ?person foaf:name ?name }
UNION
{ GRAPH ex:graph1 {?person foaf:name ?name } }
}
Result:
| person | name |
|---|---|
| ex:martha | "Martha" |
| ex:alice | "Alice" |
What about Bob?
So this is all very nice: by using FROM (or FROM NAMED) clauses we have full control over how we wish to retrieve the information about either Alice or Martha and we don’t have to rely on the specific database implementation’s whims. But what about poor Bob? His data is not in a specific named graph, after all, so how can we specify that we wish to include it using a FROM clause?
Unfortunately, there is no standardized mechanism in SPARQL 1.1 to directly address this. Various triplestores and frameworks have come up with their own solutions, by adding a (non-standard) FROM DEFAULT keyword, or introducing some "virtual" graph name that can be used as a stand-in IRI for the "unnamed" graph. Here’s an overview of various databases and the approach they have taken:
| SPARQL Endpoint Service | virtual graph name | supports FROM DEFAULT |
|---|---|---|
| Amazon Neptune | http://aws.amazon.com/neptune/vocab/v01/DefaultNamedGraph | no |
| Blazegraph | http://www.bigdata.com/rdf#nullGraph | no |
| Eclipse RDF4J | http://rdf4j.org/schema/rdf4j#nil> http://www.openrdf.org/schema/sesame#nil (legacy) |
yes |
| Ontotext GraphDB | http://rdf4j.org/schema/rdf4j#nil http://www.openrdf.org/schema/sesame#nil (legacy) |
yes |
| Stardog | tag:stardog:api:context:default | no |
So, when using Blazegraph, we can include Bob in our query results as follows:
SELECT ?person ?name
FROM <http://www.bigdata.com/rdf#nullGraph>
FROM ex:graph1
WHERE { ?person foaf:name ?name }
Result:
| person | name |
|---|---|
| ex:bob | "Bob" |
| ex:alice | "Alice" |
In RDF4J or GraphDB, we can either use http://rdf4j.org/schema/rdf4j#nil as a virtual graph name, or use FROM DEFAULT:
SELECT ?person ?name
FROM DEFAULT
FROM ex:graph1
WHERE { ?person foaf:name ?name }
And so on.
How metaphactory deals with this
Clearly, this difference between different databases poses a problem for anyone who wants their code to be independent from specific implementations. The metaphactory platform is explicitly intended to work on top of any RDF / SPARQL store. So how does metaphactory deal with this quirk?
In metaphactory, the standard admin overview of what the dataset in any database looks like shows a table with all named graphs, and the number of statements in each named graph:
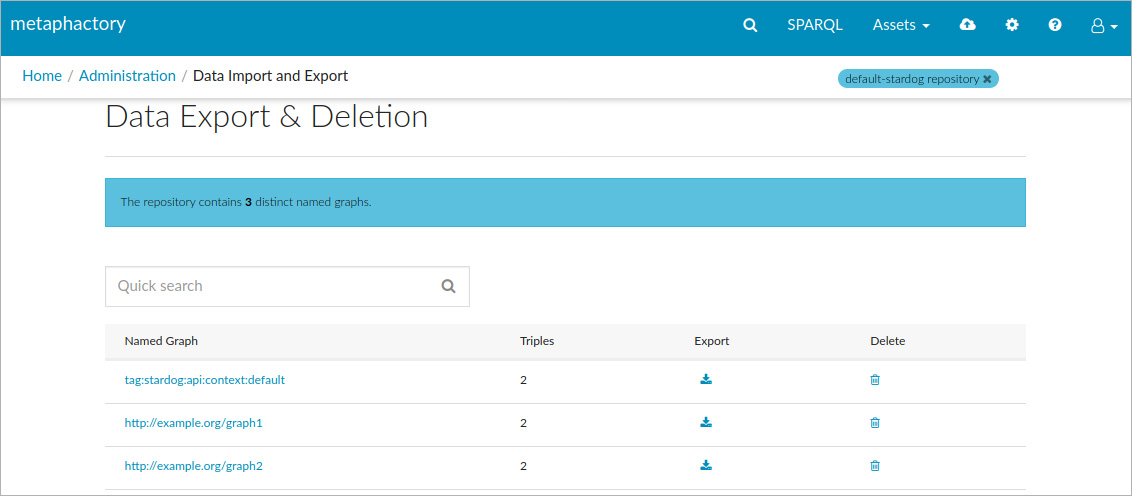
This nice tabular overview is driven by SPARQL queries, which, in the case of the named graphs, are actually pretty straightforward. But what about the default graph? In the case of default graphs, metaphactory leverages custom functionality provided by the underlying database, in particular, the "virtual graph names" we mentioned earlier. In the example table shown here, you can see this in action: there is a third named graph in our overview, named (in this case) tag:stardog:api:context:default (from which we can infer that this example was generated on top of a Stardog database).
metaphactory currently supports this same "trick" with a variety of available database solutions, including Stardog, Blazegraph, Ontotext GraphDB, RDF4J, and Amazon Neptune. However, adding this support in a way that results in a consistent representation across different database solutions would be a lot easier if there was a single, standardized, identifier for the default graph.
The lack of standardization on this is a curious oversight. metaphacts is co-authoring a SPARQL Enhancement Proposal (SEP) to the SPARQL 1.2 community group about a standardized name for the default graph, which we hope will gain traction among vendors of triplestores and find widespread implementation.
Until this is resolved, however, a simple trick to avoid the problem in the first place is this: always use a named graph to add your data. Don’t rely on the default graph.
Get started with metaphactory
To get started with metaphactory, sign up for a free trial and don’t hesitate to get in touch with us if you have any questions.
metaphactory is an industry-leading enterprise knowledge graph platform transforming data into consumable, contextual and actionable knowledge. Our low-code, FAIR Data platform simplifies capturing and organizing domain expertise in explicit semantic models, extracting insights from your data and sharing knowledge across the enterprise.
metaphactory includes innovative features and tools for:
- Semantic knowledge modeling — explicitly capture knowledge & domain expertise in a semantic model & manage knowledge graph assets such as ontologies, vocabularies and data catalogs
- Low-code application building — build easy-to-configure applications that fit your enterprise and use-case requirements using a low-code, model-driven approach
- End-user-oriented interaction — users of any level of technical experience can interact with your data through a user-friendly interface that includes semantic search, visualization, discovery & exploration and authoring
Power knowledge democratization and decision intelligence within your enterprise with metaphactory. Trusted by global enterprises like Boehringer Ingelheim, Siemens Energy and Bosch.
Sign up for your free metaphactory trial today!
Subscribe to our newsletter or use the RSS feed to stay tuned and learn about future developments on this matter.
