

Missed the Pistoia Alliance webinar, “Federated Knowledge Graphs for Scalable Data and AI in Pharma”? Check out this recap for the webinar highlights and key insights. Keep reading!
Knowledge Foundation: Federated Knowledge Graphs for Scalable Data and AI in Pharma Webinar
With an abundance of vast, complex datasets being made available daily, and an increasing pressure to accelerate research and innovation, how does the pharmaceutical industry efficiently scale its knowledge and research efforts?
A recent Pistoia Alliance webinar on Federated Knowledge Graphs offered timely guidance on how to build a data foundation that can scale. The session featured Maksim Kolchin, Product Owner at Boehringer Ingelheim, and Peter Doerr, Director of Presales at metaphacts.
In this article, we’ll recap the core takeaways and share insights delivered by our expert speakers.
Table of contents
- Setting the scene: Current attitudes towards data
- The critical challenge: data diversity and the breaking point
- Scaling obstacles: where manual work stops progress
- The Knowledge Foundation vision: abstraction and RDF
- Boehringer Ingelheim’s journey
- Technology backbone: federation with metaphacts
- Organisational and interoperability hurdles
- Summary
Setting the scene: Current attitudes towards data
The Pistoia Alliance is a global non-profit that brings together life sciences and tech partners to solve shared R&D hurdles. To gauge institutional perspectives on knowledge management and AI, we polled the webinar attendees—a mix of industry professionals, practitioners and academics. Their responses provide a snapshot of the current shift toward federated data and the practical realities of preparing pharma data for AI. The results unveiled a telling paradox: while technical proficiency is high—75% of attendees have direct experience with knowledge graphs—there is profound skepticism regarding infrastructure. A significant 84% of respondents do not believe traditional data management can effectively scale to source data for AI.

Image: A pie chart representing previous experience with knowledge graphs and ontologies.
The results also showed that familiarity with emerging concepts such as ‘knowledge graph federation’ is growing but not yet universal—just over half of respondents (52 percent) were aware of the term prior to the webinar. This suggests increasing exposure within the community but also highlights the need for continued education as federated approaches gain traction.
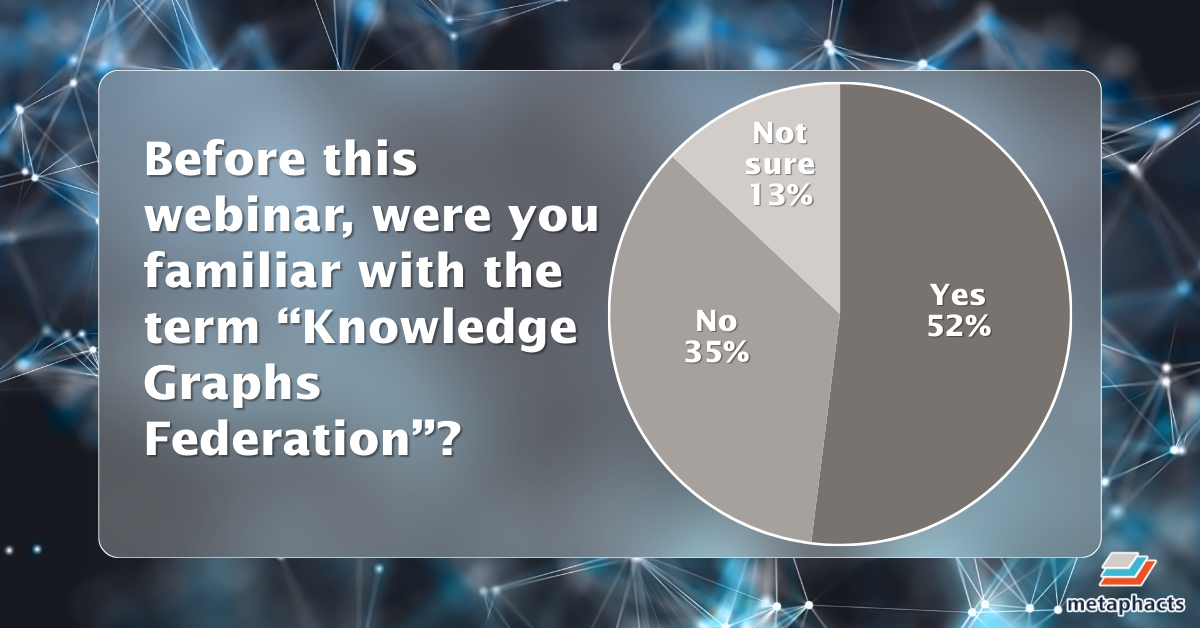
Image: A pie chart displaying participant familiarity with Knowledge Graphs Federation.
When asked about AI autonomy, the audience was notably divided. While 38 percent believed AI systems should be able to access and use data autonomously to reach their full potential, 33 percent disagreed, and 27 percent remained unsure—indicating both interest and uncertainty around the appropriate balance between automation and human oversight.
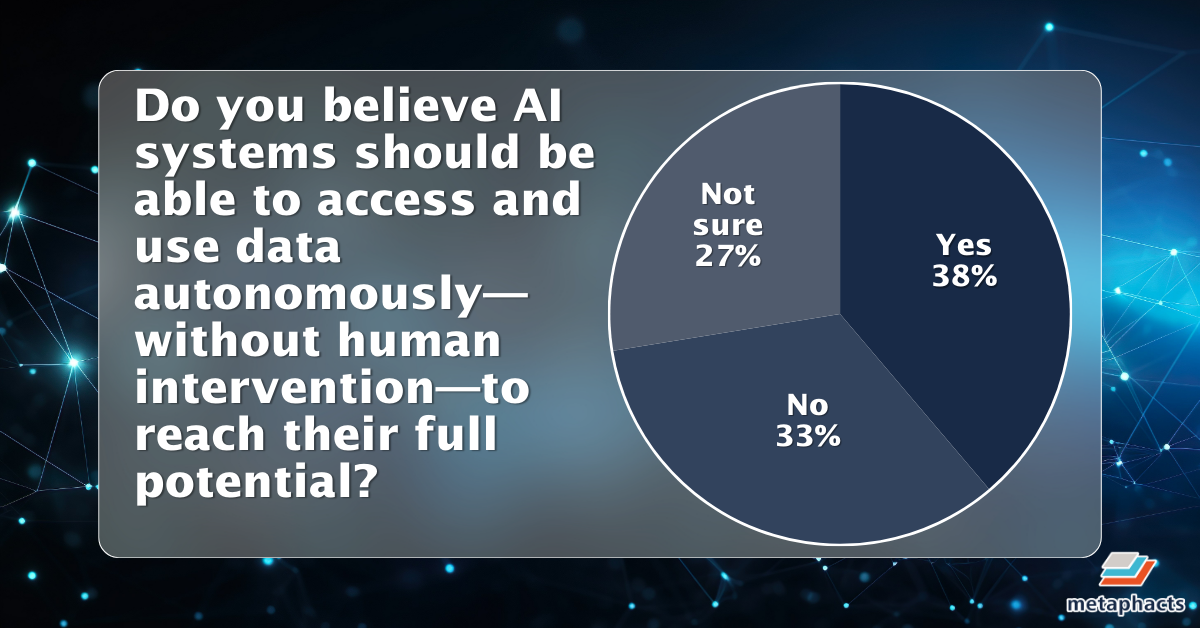
Image: A pie chart illustrating poll results on AI data autonomy.
Finally, organizational readiness emerged as a key gap. Only 30 percent reported having a governance framework capable of supporting federated data management, while the majority either lacked such a framework or were unsure. This points to a broader challenge: even as practitioners gain experience with knowledge graphs, many organizations are still building the governance foundations needed to operationalize these technologies at scale.
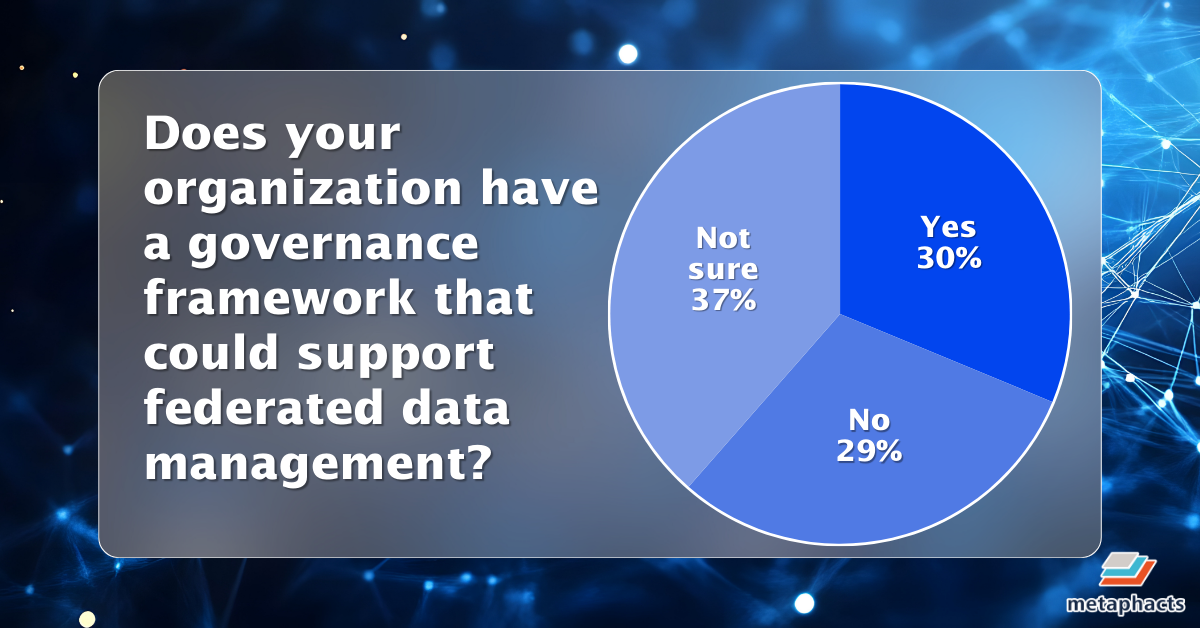
Image: A pie chart showing the status of organizational governance frameworks for federated data.
The critical challenge: data diversity and the breaking point
Maksim Kolchin argues that the existential threat to modern data strategy isn't volume—it is diversity and complexity. This manifests through surging demand across disparate business units, escalating integration costs, and inflated expectations for instantaneous, context-aware answers from LLMs.
When the friction of gathering data exceeds the value of the insight, organizations hit a "breaking point." At this stage, teams may delay critical decisions, take uncalculated risks, or even find it more economical to re-run an experiment than to locate and integrate historical data buried in legacy silos.
Scaling obstacles: where manual work stops progress
To navigate away from this breaking point, organizations must eliminate non-scalable manual labor. Maksim identified three primary hurdles: disposable pipelines that cannot be repurposed, brute-force matching caused by a lack of enterprise-wide standards, and siloed vendor ecosystems that necessitate costly, isolated data migration projects. Crucially, he warned that AI cannot fix a broken foundation; converting all data to text for vector databases or over-relying on basic protocols often just recreates manual integration effort at a different layer of the stack.
The Knowledge Foundation vision: abstraction and RDF
The solution lies in creating an abstraction layer—a "Knowledge Foundation." Much like TCP/IP abstracts the complexities of networking, this layer shields consumers from the underlying messiness of data storage. For consumers, AI agents interact with a unified catalog to prevent "context window overload." For producers, data owners maintain a single, authoritative Knowledge Graph rather than creating bespoke extracts for every new requester.
This architecture relies on vendor-agnostic standards like RDF and SPARQL. By treating relationships as "first-class citizens" and utilizing global unique identifiers, organizations can finally realize the FAIR principles (Findable, Accessible, Interoperable, Reusable) in a truly automated ecosystem.
The Knowledge Foundation vision: abstraction and RDF
To manage complexity at scale, an abstraction layer is needed. Maksim compared this to how TCP/IP simplifies network communication or how high-level languages abstract hardware execution. A knowledge foundation plays this role for data.
For consumers, applications such as AI agents and ML pipelines should be able to interact with this layer without knowing where the data sits, how it is structured or what format it is in. An AI agent could simply check a catalogue to see what is available and ask a question in a query language, reducing noise and avoiding context window overload.
The technical foundation comes from domain-owned Knowledge Graphs built with the vendor-agnostic standards RDF and SPARQL. Global unique identifiers allow domains to connect, similar to explicit and consistent primary and foreign keys, but treating connections between entities as first-class citizens.
The overall approach fits naturally with the FAIR principles. FAIR data means data that is Findable, Accessible, Interoperable and Reusable—evolving the possibilities of what you can accomplish with your data and how to govern it. The structured, semantic and standardized nature of knowledge graphs provides the necessary architecture to move data from isolated silos into an ecosystem that fully meets the requirements of the FAIR principles.
For producers, this model improves productivity by letting data providers maintain a single, authoritative instance of their data as a Knowledge Graph instead of producing multiple versions for multiple consumers.
Boehringer Ingelheim’s journey
Boehringer Ingelheim is moving towards this federated enterprise-wide approach, says Maksim, describing three core focus areas:
- Self-service and self-learning UX to support users who are new to Knowledge Graphs.
- Controlled vocabularies as a practical starting point for automation and reducing duplicated effort.
- Hypercare support for high-value use cases to build success stories and momentum.
Current successes include omics data management, where researchers have reduced time to insight by a factor of three, and supply chain scenarios where managers can obtain answers from one place rather than searching across several IT systems.
Technology backbone: federation with metaphacts
metaphactory and its AI extension metis, is a knowledge-driven AI platform supporting the creation and management of a semantic layer, and the platform enables federation through two approaches:
- FedX, an open-source RDF framework that enables transparent SPARQL federation so developers do not need to know where data is stored. Boehringer Ingelheim began with this to enable browsing across graphs.
- EPHEDRA, which connects to non Knowledge Graph sources like REST APIs or SQL databases by creating a virtual Knowledge Graph from external API calls.
Discover how federation with metaphactory works.
Overcoming organisational and interoperability hurdles
Navigating the transition to a Knowledge Foundation requires more than technical implementation; it demands a shift in organizational strategy and culture. To achieve true interoperability and overcome institutional resistance, we recommend the following approach:
Prioritize modularity and governance
Avoid the pitfall of building a single, monolithic ontology. Instead, focus on modular designs that mirror modern software development, utilizing clear ownership and rigorous versioning. For these systems to be AI-ready, ontologies must be designed with "LLM-readiness" in mind—prioritizing semantic clarity and a manageable size so that models can interpret the data structure without ambiguity.
Lead with concrete value
To mitigate resistance to change—particularly among teams entrenched in traditional SQL environments—demonstrate tangible utility at the outset. Rather than attempting a wholesale replacement of existing tools, focus on how a Knowledge Graph solves a specific, high-friction bottleneck. Improving a single, visible process creates the internal buy-in necessary for broader adoption.
Standardize to avoid divergence
In a landscape where widespread solutions for ontology variety are still emerging, it is critical to resist diverging practices. Organizations should align with industry standards to ensure that data remains interoperable across domains and future-proofed against evolving AI requirements.
Ultimately, building a Knowledge Foundation is like constructing a unified high-speed rail network. When every domain lays its own track using a standard gauge, the result is a seamless ecosystem where applications and AI agents travel freely across the entire organization. By removing the need for manual rerouting and bespoke integration, you transform your data from a collection of static silos into a dynamic, scalable engine for innovation.
Start your knowledge graph journey today
If these challenges around data diversity, integration costs and scaling data management for AI feel familiar, our team would be happy to discuss how Knowledge Graphs could support your data foundation. Chat with an expert!
Ready for a deeper dive? [Watch the full webinar on demand here.]