
When it comes to leveraging your enterprise data, having a wealth of quality data is only half the battle. The other half is having the right tools and technology to help you extract valuable insights from it and uncover new opportunities. That’s why we were eager to introduce metaphactory's Next-Generation Semantic Search (Next-gen Search), as part of the metaphactory 5.0 release.
metaphactory's revamped semantic search component introduces a new level of flexibility and precision when defining search queries, enabling end users to enjoy the full range of knowledge discovery and decision intelligence. Users can simultaneously find quick and precise answers to their queries or freely explore the deepest depths of their knowledge graph.
We listened to user feedback and wanted to deliver a version even more powerful and intuitive than the previous version. This upgrade combines many of metaphactory's search paradigms into a single user experience. Next-gen semantic search makes it easier for end users to find what they need fast, as well as gain a deeper understanding of their data, opening the door to making new discoveries. Meanwhile, application engineers benefit from easier configuration and maintenance of the search interface.
In this blog post, we'll discuss the new and refined elements of Next-gen Search and demonstrate how it works in metaphactory. Keep reading!
Table of contents
- Semantic search: More than just keywords
- metaphactory's new and improved semantic search: An all-encompassing search tool
- Next-gen Search features
- Summary and outlook
- Try it yourself
Semantic search: More than just keywords
Before diving into the mechanics of next-generation semantic search, we will discuss how semantic search, more broadly, differs from the more traditional search methods you may already be familiar with.
Keyword search is a method that generates results based on literal string matching, requiring queries to include exact keywords and operators like "and" and "or" to narrow or broaden the scope. This type of search engine produces results that include the entered keyword in the abstract, title or any indexed content. Keyword search is commonly used in library systems, research databases or within documents. Although a fairly simple method and one that has been used for many decades, it has limitations that hinder searchers from quickly and precisely finding relevant information.
Limitations of keyword search
A major limitation of keyword search is its lack of precision and reproducibility. This is mainly due to the inability to comprehend and lock the semantics or meaning behind a query and that it disregards the context and relationships between keywords. This lack of comprehension and the ambiguity of keywords can lead to thousands of results that aren't actually relevant to the searcher. Because keyword search is based on keyword matching, the relevance of a result is often measured by the number of times a target keyword appears in the content title or text, rather than by the relevance of the content itself. You’d have to use a precise combination of keywords and operators to narrow down the context—and even then, being too specific might inadvertently exclude more pertinent answers.
Let's say you want to learn more about 'ethanol'. If you enter 'ethanol' into the search bar of a keyword engine, it may generate hundreds of thousands of results. But of these results, how many are actually relevant to your needs? Ethanol has many applications and keyword search isn’t capable of disambiguation or distinguishing whether you are searching for information about ethanol as a drug ingredient, fuel, fermentation process or alcohol in a beverage. You can attempt to specify the context by adding additional keywords like ‘ethanol’ + ‘fuel’. The engine will then display results that include ‘ethanol’ and ‘fuel’ in the document or publication, but it does not indicate the content’s actual relevance around the topic of ethanol as a fuel, it simply means that the entered keywords are present.
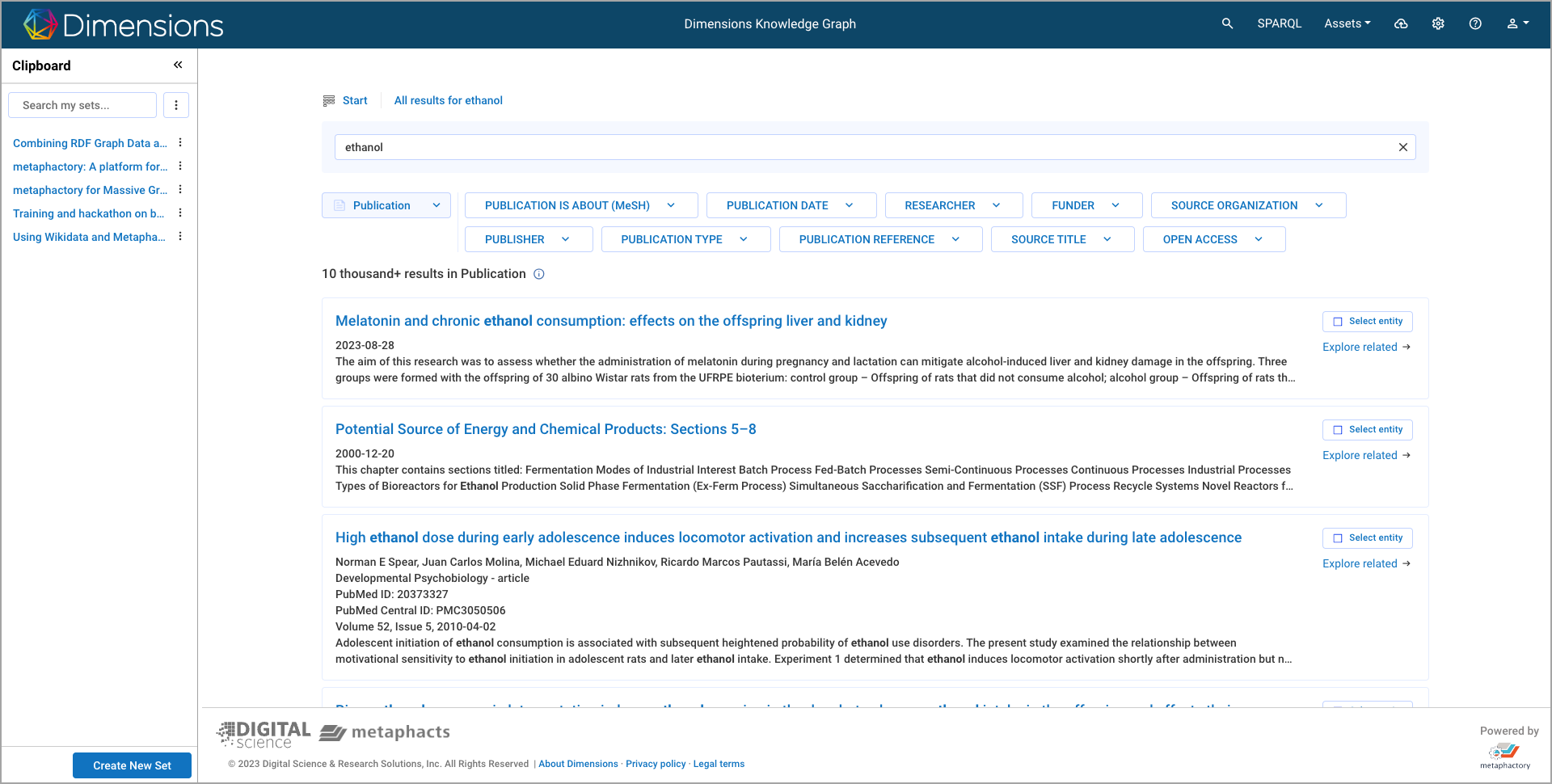
Next-gen Search with keyword functionality. Thousands of results matching the keyword "ethanol", however, the context of the keyword is diverse, i.e., the user needs to read the title and abstract to understand that the first publication is about ethanol as an alcohol and its impact on the liver and kidney, whereas the second publication matching the same keyword is about ethanol as a fuel.1
In summary, keyword search can be characterized as follows:
- Results are generated by matching the query keyword with content that has the keyword in the title or any other full-text indexed contents
- Usually doesn't detect synonyms of keywords
- It doesn't consider context, intended meaning or applications of the keyword entered
- May offer support for local logical operators (e.g., "and", "or") to combine keywords and to broaden or narrow search results. However, these operators can not relate keywords semantically but just determine whether words appear together in a text.
While keyword search can significantly extend the time spent searching for relevant results and make it difficult to pinpoint specific content, it is an essential and necessary search method that fulfills basic search and data needs, particularly when the user's information need is broad or lacks initial context.
What is semantic search?
Semantic search is a search method that uses semantic technologies to understand the contextual meaning of a query and generate relevant results. The goal is to guide the user when expressing their information needs and produce results with precision and accuracy.
Unlike keyword search, semantic search prioritizes content most relevant to the query based on the search parameters set by the user (if any) and proves relevance through explicitly defined semantics and the interlinking of entities in the knowledge graph that powers the search. It suggests content not based on plain phrase or keyword matching, instead it considers the different contextual interpretations of keywords. Behind the semantic search engine is a semantic knowledge graph that explicitly captures the relations between entities in a dataset, and also the meaning of different entity types. This explicitly defining of semantics enables semantic search to provide answers to a variety of information needs with a high degree of expressiveness and precision.
For instance, if you were to input 'ethanol' into a semantic search engine, it would present you—while still typing—with options to narrow your query based on the different semantic interpretations of ethanol (that have already been explicitly defined in the knowledge graph) without having to enter additional keywords.
The benefits of semantic search
- Retrieves knowledge from richly structured data sources using a semantic representation based on open W3C semantic web standards and FAIR principles
- Enhances search precision & speed by seeking to understand the user's search intent and contextual meaning of the keywords entered through semantic entity disambiguation
- Prioritizes and ranks results based on contextual relevance
Your data already has the knowledge within it to support decision intelligence—you simply need to unlock and harness its full potential. Leveraging semantic search for your enterprise data means being able to surface pertinent information swiftly and with accuracy and gaining the ability to explore and access the entirety of your domain knowledge.
metaphactory's new and improved semantic search: An all-encompassing search tool
metaphactory's next-generation semantic search improves on our existing semantic search framework with enhanced flexibility, ultimate precision and harmony with user needs; while leveraging the strengths of semantic search.
metaphactory has always supported different search paradigms, but these were initially offered as individual components, each catering to specific information needs, data modalities and user interaction patterns.
Next-gen Search caters to all user information needs and interaction patterns addressed by the former individual components in one unified interface. This consolidation makes configuration and maintenance easier for application engineers and allows end users to experience the full range of search depending on their specific info needs. Additionally, Next-gen Search facilitates knowledge democratization through its interactive and user-friendly interface, so that anyone across the enterprise can execute queries and review results.
Addresses all search and information needs
A defining element of metaphactory's next-gen semantic search is its capability to support the full spectrum of user information needs, from unspecific and explorative to specific and targeted searches. Its combination of total flexibility and precision enables you to search boundlessly and without constraint, fluidly and intuitively transitioning between search approaches, spanning the entire range of information needs during their search journey.
Users starting with an open and explorative approach may want to explore their knowledge graph with no specific question or defined objective in mind. They might not know exactly what information they're looking for and may simply want to discover what information is available to them. On the other hand, users with a defined question or a clear idea of the answer they are searching for may have a more specific and targeted need.

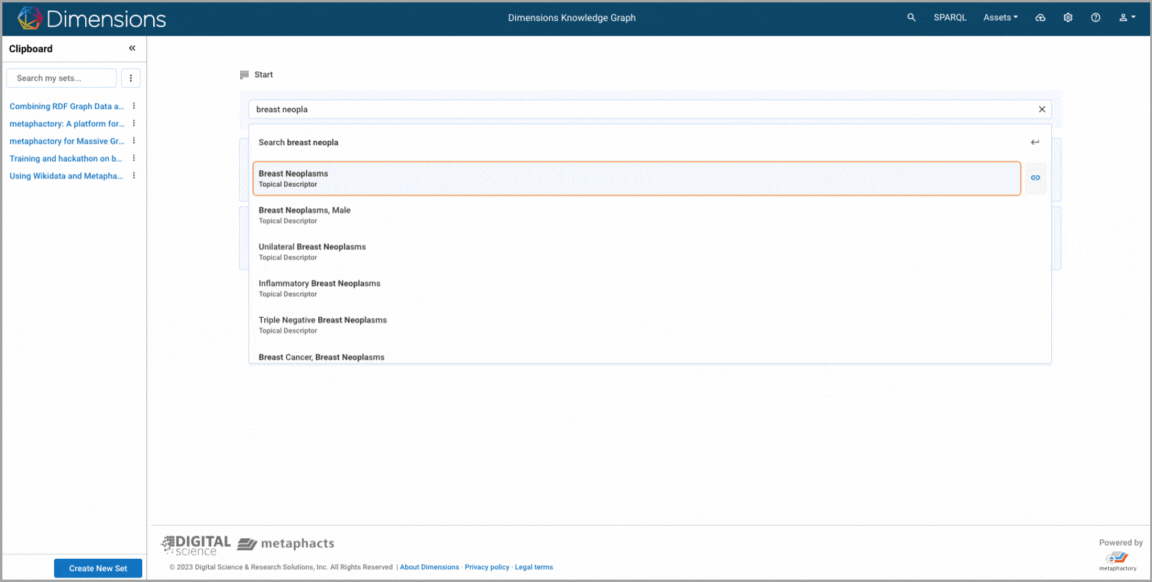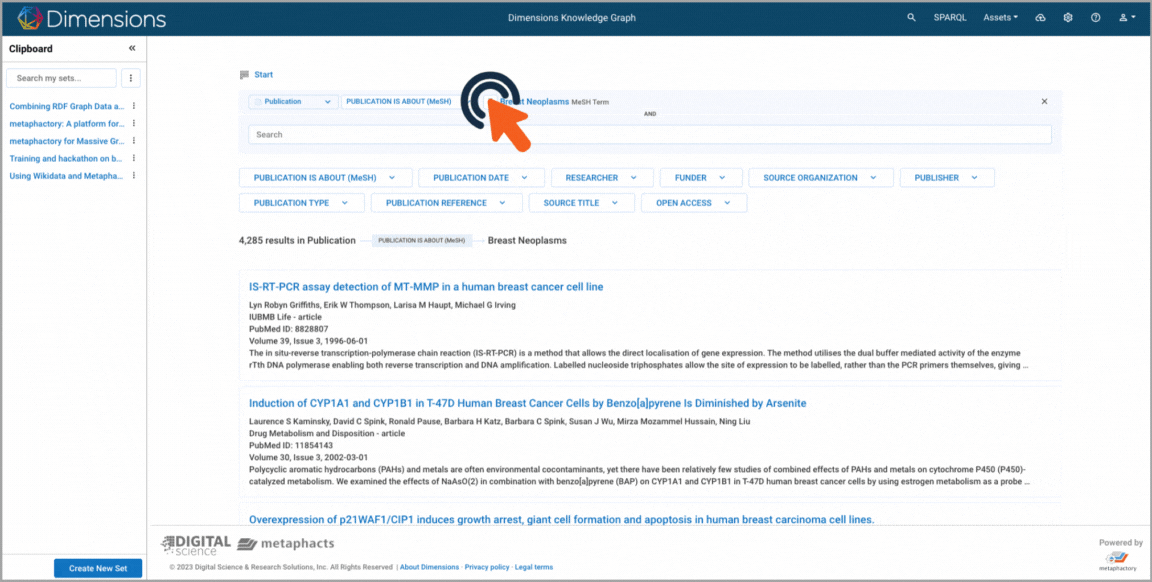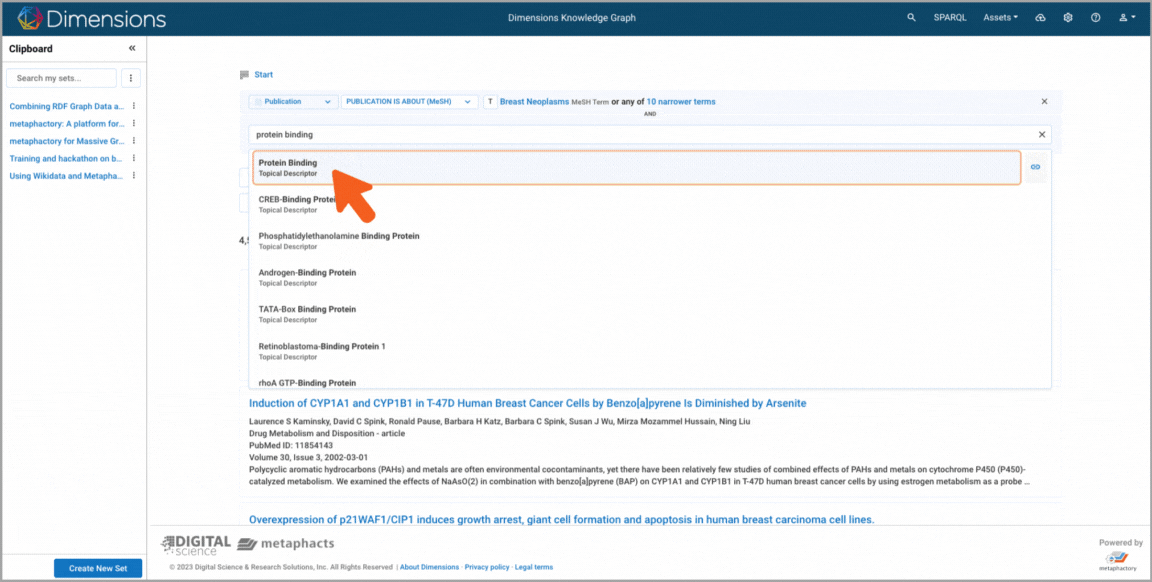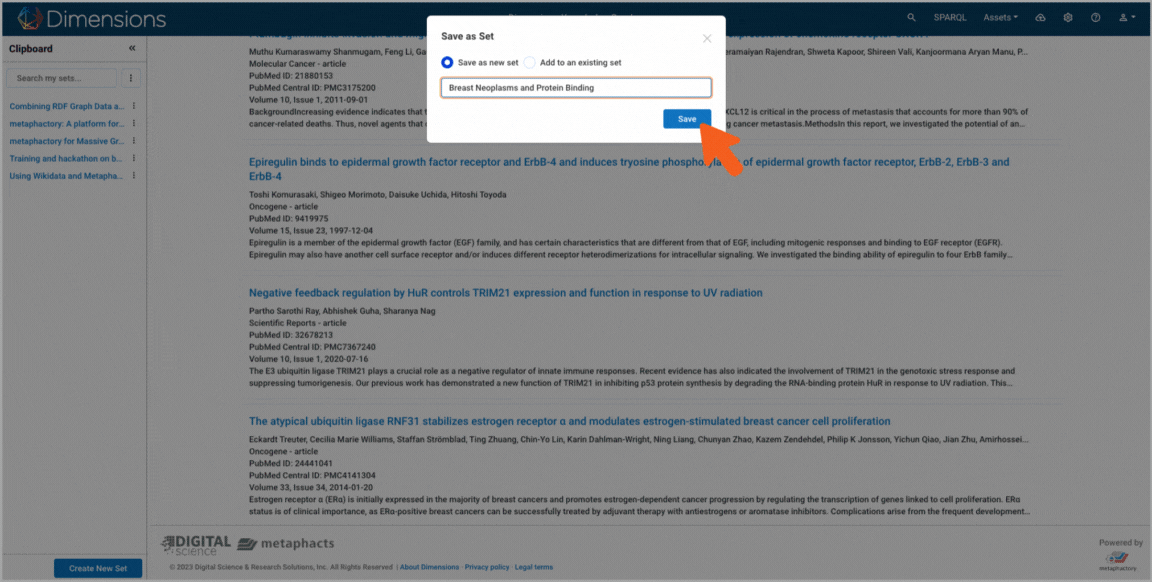
Explorative search where the user looks at available publications that use the keyword “breast neoplasm” and further scopes down the search results by date and by topic ("protein binding"). 1
Next-gen Search's versatility ensures you can always transition between these needs at any given moment. You can freely explore the different entity types or examine the relation between different entities and entity types following the relations in the underlying semantic model. For example, you can browse organizations, publications and clinical trials among other entity types. As you browse organizations you may want to explore how a specific organization (like the Charité Berlin) or a set of different organizations is semantically related to other (types of) entities. You can then incrementally become more focused and restrict your search. Alternatively, right from the start, you can formulate a very targeted query by restricting the search domain to a particular entity type and by pinpointing a relation to a specific semantic entity, for example, to find all Publications that are funded by the Charité Berlin.
Targeted search where the user leverages the explicit semantic relations in the graph to search for publications about the topic "breast neoplasm", refines their search to include all subtypes of the topic based on the underlying semantic vocabulary, and adds a second condition on the topic ("protein binding"). Finally, the user saves their search results as a set for later use. 1
Supports different search paradigms and data modalities
The improved search's hybrid nature is reflected not only by its flexibility in guiding users along their search journey depending on their information needs, but also by the way these information needs can be answered over different data modalities – from unstructured text to rich structured data. Searching using a combination of unstructured text (employing a simple keyword search using strings) with structured data (leveraging the richness of structured data using semantic relations) enables a user with hybrid needs to narrow the scope of their search and retrieve results with precision. Next-gen Search has the versatility and functionality to support all paradigms in one single component and user experience, giving users the freedom to search and discover knowledge in the way they prefer or their data pre-determines.
This hybridity is particularly achieved through a combination of traditional keyword search and semantic faceted filtering, which helps to refine your search and narrow down results based on explicit semantics.
Simplified, model-driven configuration
The integration of metaphactory's individual search components into one reduces the need for extensive configuration because application engineers only need to configure and maintain one component instead of multiple. It also eliminates the need to decide which search approach or component is the most suitable for a project (which can be proven outdated over time and lead to reconfigurations).
Most importantly, since metaphactory 5.0, the search now supports a fully model-driven configuration. A search profile is created automatically by simply referencing relevant classes from an ontology. This not only significantly reduces the time needed for application engineers to set up a search, but also greatly minimizes the maintenance of the overall configuration code, which would otherwise need to be manually kept in sync with future changes to the model. At the same time, it offers the flexibility to perform more selective configuration changes—possibly beyond what can be automatically derived from the model—to align with specific end-user needs incrementally.
Next-gen Search features
Here is a list of all the features and functionalities you can expect with metaphactory's Next-gen Search:
- Supports keyword, structured and hybrid searches and thereby unifies several different search paradigms into a single user experience
- Search engine auto-completion and semantic lookup and disambiguation of entities, including terms and their synonym from controlled and structured vocabulary
- Faceted filtering for interactive and iterative query refinement and exploration
- Ability for users to expand their search results based on controlled and structured vocabularies
- Allows interaction with search results, i.e., it supports saving of searches as queries or as sets of entities to be organized and reused for subsequent searches or analytical tasks
- Is model-driven, meaning that search configuration can be automatically derived from the constraints as provided by the ontology significantly lowering the initial setup and maintenance effort. In addition, it also means that improvements, for example, to the structure of a vocabulary will immediately benefit end users’ search capabilities.
All the functionalities offered with metaphactory's Next-gen Search ultimately grant you maximum control over how you search, whether that's taking an explorative or more targeted approach to your research. It provides you with flexibility in addressing your information needs, such as enabling flexible access to different data modalities, spanning from highly structured to unstructured data sources. Additionally, it equally supports the construction of expressive and precise queries over highly structured data, as well as the execution of keyword search results on unstructured data—eliminating the need to handle any technicalities.
Summary and outlook
In the previous decades of keyword search engines, finding data was never an issue, the challenge was always finding the right data. This predicament partially resulted from imprecision, low expressivity, lack of explicit factual knowledge and contextual semantics. Consequently, it necessitated additional human labor to assess the relevance of each search result individually and resulted in the inability to reproduce search results reliably. Even in the new age of Large Language Models (LLMs), similar problems persist. While LLMs are great as universal human-computer interfaces (HCI), with their unmatched ability to process and generate natural language, the answers they generate are based on the stochastic prediction of tokens rather than explicit, factual knowledge. As a result, it again requires additional work to verify and assess the trustworthiness of its answers.
With metaphactory's Semantic Search capabilities, we enable end users to access factual knowledge managed in semantic knowledge graphs easily and efficiently. With the latest Next-gen Search component, as introduced with metaphactory 5.0, we have unified various search paradigms into a single user interface to benefit end users and application engineers equally. In our latest metaphactory 5.1 release, we have added several features to increase its expressivity and to further exploit model knowledge, for example, in the form of controlled and structured vocabularies during the query formulation process.
Concurrently, we strongly believe that LLMs will have a role in metaphactory’s future semantic search capabilities. In particular, LLMs will benefit metaphactory’s semantic search capabilities by serving as a generic human-computer interface and lowering the barrier for user interaction.
We have developed an initial evaluation prototype in metaphactory 5.1, enabling users to express their information needs in natural language. With the help of an LLM, we can detect entities within the question, match them to semantic entities in the knowledge utilizing metafactory’s new entity lookup, and then translate the question into an explicit SPARQL query to be executed over your own, factual knowledge graph. We see this as just one example of how metaphactory and knowledge graphs can compensate for the shortcomings of LLMs while harnessing their strengths.
Try it yourself
To see how metaphactory's next generation semantic search works in practice, you can get started with metaphactory today using our free trial.
metaphactory is an industry-leading enterprise knowledge graph platform that helps you to transform data into consumable, contextual and actionable knowledge. Our low-code, FAIR Data platform simplifies capturing and organizing domain expertise, extracting actionable insights from your data and sharing knowledge across the enterprise.
metaphactory includes innovative features and tools for:
- Knowledge management — manage your knowledge graph assets, data & query engineering and data quality in one place
- Low-code application building — build easy-to-configure applications that fit your enterprise requirements like data access services, middleware services, model-driven application building
- User-friendly interface — users of any level of technical experience can interact with your data through a user-friendly interface that includes search, visualization, discovery & exploration, authoring and end-user knowledge management
Get your free trial of metaphactory
Footnotes
1 The screenshots and screen-captures used in this blog post show a prototype of the Dimensions Knowledge Graph, powered by metaphactory's next-generation semantic search capabilities. By leveraging the latest capabilities of metaphactory to enhance discovery and decision intelligence, the Dimensions Knowledge Graph will help users in pharma and life sciences to harness the synergy of global research knowledge alongside AI-powered applications to improve business decisions. Currently in an early access stage, the Dimensions Knowledge Graph is scheduled to be officially launched in April 2024.

