
This article is the first in a series of two where we discuss our perspective on what is considered a semantic knowledge graph, why it's important, and share how they can drive your enterprise goals forward.
The importance of the semantic knowledge graph
Have you ever been in a conversation where someone mentioned a "knowledge graph," only to realize that their description was completely different from what you had in mind? Just a few years ago, a harmless mix-up like this one would hardly catch anyone's attention. With the rapid advancements in artificial intelligence, machine learning and hyper-automation that are reshaping our work, shopping and web surfing experiences today, the significance of the knowledge graph has amplified in our present digital landscape, and understanding what they are and how they work is vital to unlocking its immense potential.
The growth of large language models drives a need for trusted information and capturing machine-interpretable knowledge, requiring businesses to recognize the difference between a semantic knowledge graph and one that isn’t—if they want to leverage emerging AI technologies and maintain a competitive edge.
This article is the first in a series of two where we discuss our perspective on what is considered a semantic knowledge graph, why it's important (specifically in the context of AI and LLMs) and share how they can drive your enterprise goals forward.
Table of contents
- What is a knowledge graph?
- Key characteristics of a semantic knowledge graph
- Why there's confusion around the term "knowledge graph"
- The three layers of a semantic knowledge graph
- Layer 1: The Instance Data Layer
- Layer 2: The Vocabulary Layer
- Layer 3: The Semantic Layer (Ontology Layer)
- Unlock the full potential of your data
What is a semantic knowledge graph?
A semantic knowledge graph is a large network of entities representing real-world objects, like people, organizations and abstract concepts, such as professions and their semantic relations and attributes, through a visual graph structure. While many other varying definitions exist, our definition of the knowledge graph places emphasis on defining the semantic relations between these entities, which is central to providing humans and machines with context and means for automated reasoning.
Unlike traditional database systems, a semantic knowledge graph goes beyond the simple storage of data and focuses on the definitions of entities and the connections between them. For example, in a security use case, it is critical to understand the connections between systems and their mutual impact to detect and prevent malicious activity. Without a knowledge graph to explicitly capture and expose these relations, vulnerabilities in systems and potential threats could go unnoticed.
What makes a knowledge graph a semantic knowledge graph, and a unique and powerful data solution, is the semantic (data) model, or ontology, that is part of it. We use the terms semantic model, semantic data model and ontology interchangeably to refer to formal and explicit definitions of the concepts and relations within a domain. An ontology enriches data within a knowledge graph with context and meaning that humans and computers can interpret. It's like a powerful lens that grants you a holistic, bird's eye view of your data, revealing intricate hierarchies, precise definitions and crucial context; it unlocks unparalleled access to the deepest layers of interpretation, empowering you to grasp the essence and true meaning of your data.

Example of a knowledge graph
Watch this short video for an example of how semantic knowledge graphs can add value in your workplace:

Watch: What is a knowledge graph?
We believe that without an ontology, a knowledge graph is simply a graph structure that captures interlinked data. The added contextual richness promotes comprehensive analysis and knowledge creation and sharing that was previously unachievable.
In a previous blog post, we define an ontology as:
“A semantic data model that defines the types of entities that exist in your domain and the properties that can be used to describe them. An ontology combines a representation, formal naming, and definition of the elements (such as classes and relations) that define the domain of discourse.”
While a knowledge graph can exist without an ontology, an ontology is often represented in a knowledge graph because of the natural human desire to organize data—visually or in structure. You can still apply an ontology to data that is unstructured or data that is not highly connected, but often it is transferred into a knowledge graph. It's also possible to import or create an ontology in a knowledge graph to model your domain without loading data, which is extremely beneficial in some use cases.
Watch this video for a quick explainer of the semantic model:

Key characteristics of a knowledge graph
-
Semantically modeled: It has a semantic layer that contextualizes data, embedding meaning through representation, formal naming, and the definition of elements.
-
Machine-interpretable: Designed to be processed, analyzed, and interpreted by humans and machines.
-
Relations as first-class citizens: The knowledge graph uses nodes, edges, and labels to depict entities, relationships, and properties.
-
Follows open standards: Follows open standards enabling reusability, interoperability, and collaboration. (e.g. W3C web stack)
-
Flexible: The knowledge graph can be adapted to accommodate changes in the domain, allowing it to grow and evolve.
-
Harmonized: Has a standardized way to define a vocabulary (also referred to as a taxonomy), so that the data is clear, consistent, and organized.
-
Queryable: The knowledge graph can be queried using natural language or structured queries, enabling users and machines to quickly and easily retrieve relevant information.
-
(Optional) Federated: Ability to incorporate data from disparate sources to create a more comprehensive view of the domain represented.
How you define your data is integral to the way you store and address it, which is why those ontologies and semantic models are important. To maximize the full potential of a knowledge graph, we believe it should fulfill the requirements above because a knowledge graph that is flexible, semantically rich, and that humans and machines can understand, interpret, and use encourages significant opportunities in uncovering hidden knowledge, accelerating data literacy in your enterprise and building trustworthiness in your data.
Our enterprise knowledge graph platform, metaphactory, makes it easy to leverage semantic technologies and build a knowledge graph with these characteristics. It comes with a low-code, user-friendly platform, semantic search functionality and semantic knowledge modeling that stakeholders across the business can contribute to and understand.
metaphactory has countless applications in engineering, finance, pharma and life sciences use cases like drug discovery or fraud detection. It was created based on a stack of open standards as part of the W3C's Semantic Web initiative, also known as the Semantic Web stack, ensuring interoperability, reusability and collaboration.
If you have data you want to optimize and extract knowledge from, check out metaphactory and see how it can help your enterprise.
Why there's confusion around the term "knowledge graph"
Knowledge graphs have been around for decades, so why is there still a considerable amount of confusion about what they are and how they differ from ontology or vocabulary, even among professionals in the knowledge management space?
It boils down to three reasons:
- Evolving industry terminology: Even within the industry, there have been significant changes in naming. In fact, knowledge graphs evolved from 'Linked Data' and the ‘Semantic Web’, and new terminology could become more prominent again in the next five years.
- Marketing hype: Because the knowledge graph is experiencing a revival for its potential to enhance the accuracy and efficiency of AI-based applications, many vendors are eager to call their solution a knowledge graph even when it isn’t.
- Semantic barriers: Terms can have multiple meanings in different languages and industries. For example, for years, 'ontology' was used in pharma to describe something that the semantic web and knowledge graph world would actually consider a taxonomy or vocabulary.
Our description of a knowledge graph takes these misconceptions into consideration and is, in our opinion, a comprehensive definition of what a knowledge graph should consist of and how it should operate. To further clarify and demystify what we consider a true knowledge graph, we’ll review the three distinct layers that form a semantic knowledge model.
The three layers of a semantic knowledge graph
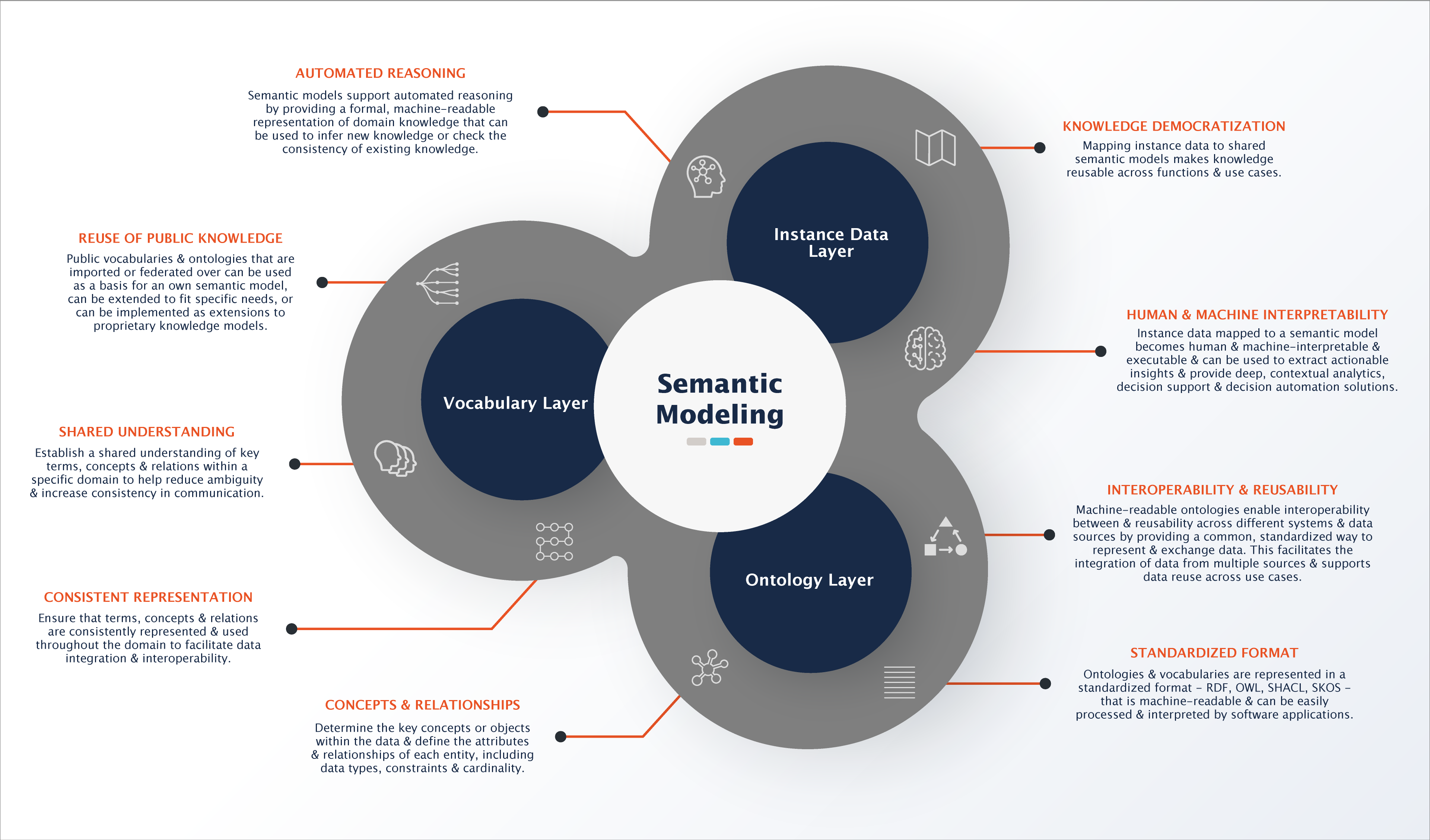
Layer 1: The Instance Data Layer
The first layer of the knowledge graph is the Instance Data Layer, which captures instance data and its relations. This layer is a step ahead of relational databases because you can query along these relations and across multiple data sources. For example, in the graphic below you'll see that this layer records the explicit definition of entities and their relationships.

The Instance Data Layer
While it is a foundational layer for any graph structure, it has limitations and cannot facilitate automated reasoning, contain logical mapping or be interpreted by machines.
There are also consistency limitations in this layer, the classification of companies may need to be more consistent between different source systems due to diversity in terminology. Ideally, it would be integrated into one uniform set of terms, which is why the second layer becomes crucial.
Layer 2: The Vocabulary Layer
The secondary layer, or Vocabulary Layer, is where we use a set vocabulary to define the terms used across disparate systems and departments. It's common for enterprises to have multiple data systems and heterogenous data sets using varying terminology for similar concepts.
We cover the topic of vocabulary in a previous blog post, defining it as:
“A collection of terms organized in a (hierarchical) classification scheme. A term could include preferred and alternative labels and has a defined scope or describes a specific domain. The most common examples of different types of vocabularies are thesauri, taxonomies, terminologies, glossaries, classification schemes, and subject headings.”
For instance, if one department describes a job title as "Assistant Regional Manager," and another labels the position as “Secondary Regional Manager,” it can lead to duplications, confusion, and inconsistencies when being read by humans or machines.
Some examples of public vocabularies include STW thesaurus for economics and MeSH. By using consistent representation, all stakeholders—from business executives to knowledge graph engineers—can have a shared understanding of key business terms and concepts within their domain. It promotes a more consistent and accurate representation of knowledge, makes interoperability easier, and encourages knowledge creation. It’s also possible to leverage public taxonomies and vocabularies as extensions for proprietary knowledge models to fit specific needs and use cases.
The example below shows how we classify companies based on different terminologies in different systems, but integrate this into a consistent structure (i.e. taxonomy) so we can later refer to it and correctly evaluate its class.
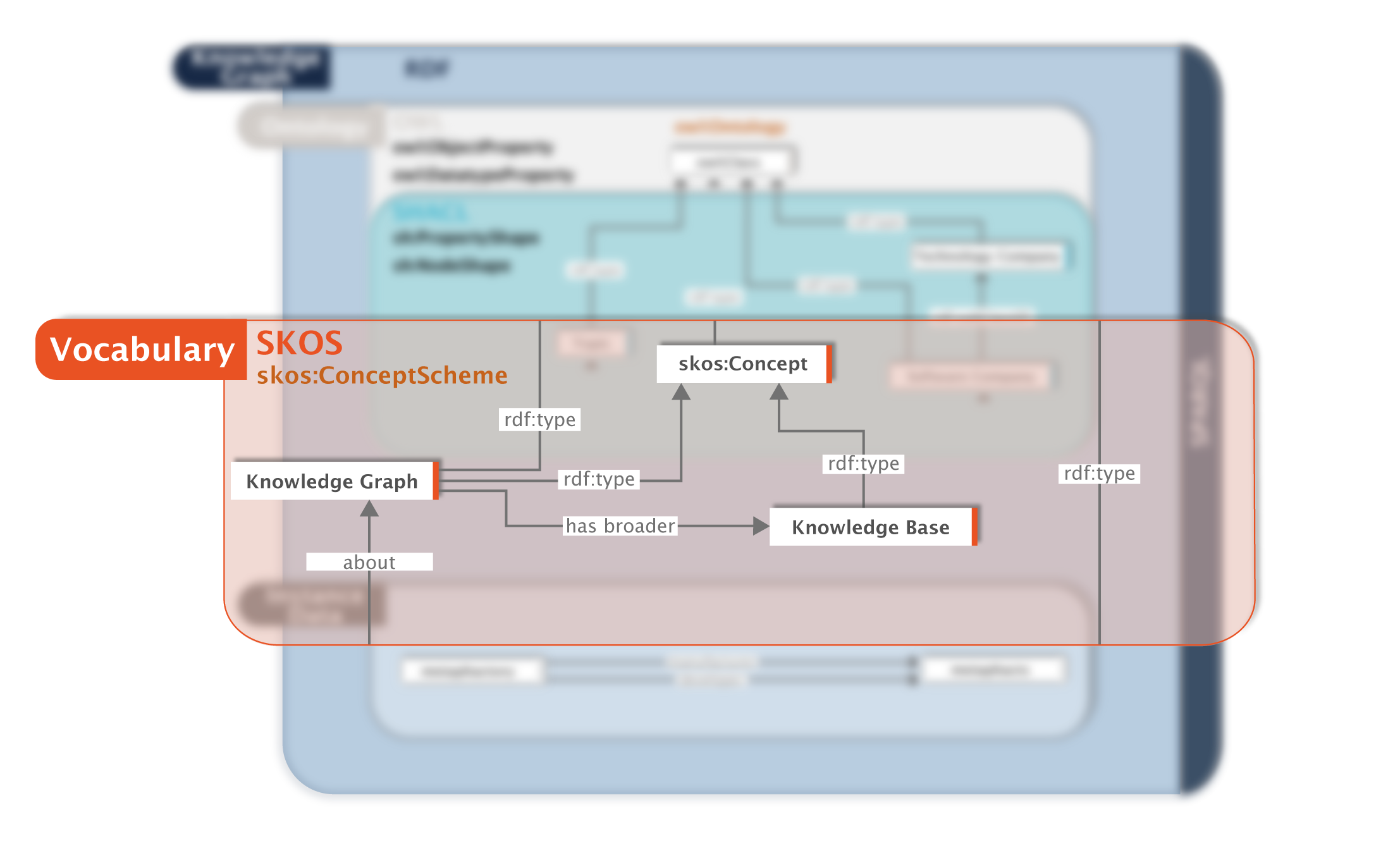
The Vocabulary Layer
It's important to note that not all knowledge graphs contain this layer. Human involvement is required to create the definitions and shape the vocabulary; this manual process is essential for creating uniformity across disparate systems.
While the vocabulary layer already takes the instance data to the next level, there is still so much more that we want the machine to understand, which can be done on the 'schema' level or the semantic layer.
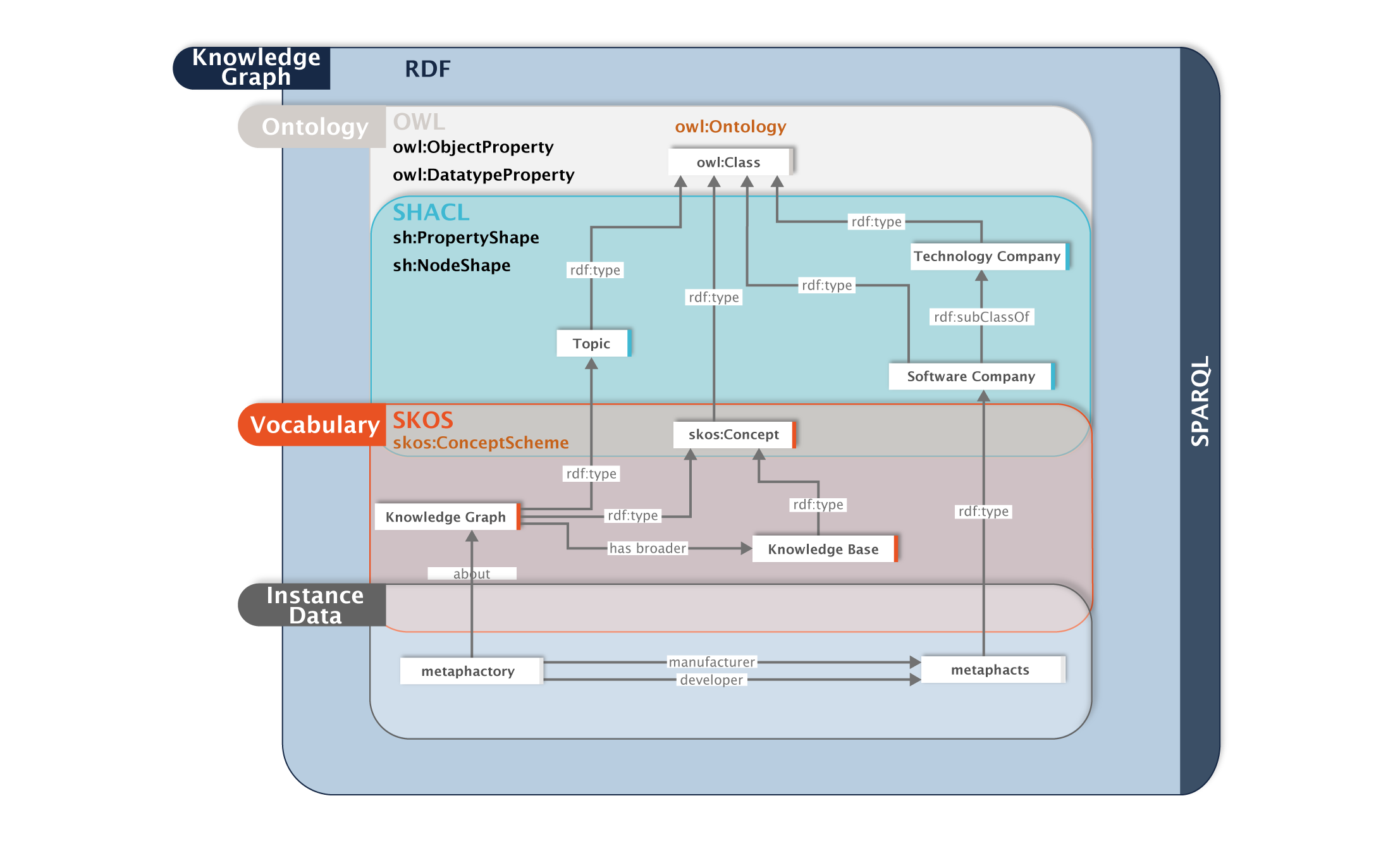
Layer 3: The Semantic Layer (Ontology Layer)
The ontology layer is arguably the most important yet often overlooked layer in the knowledge graph. This specific layer differentiates a simple graph structure from one that allows you to discover meaningful knowledge because it enables you to model the meaning of your data and teaches machines what to make out of all this information.
While vocabularies help you to organize, annotate and query the knowledge graph on a terminological level, ontologies work on the logic level, supporting the development, maintenance and queryability of the knowledge graph. It also provides the foundation for reasoning that machines operate with, because it represents the logical definitions (or logical axiomatizations) of what entities and relations are, as well as being able to facilitate the construction of rules. For example, an ontology can define that a person has a role in a company, while a vocabulary can describe those roles using a controlled vocabulary (sales manager, receptionist, regional manager, etc.).
This semantic layer helps computers understand the concepts of a company, supplier, process, and product, and how they are interconnected. Without a semantic knowledge graph, a machine or human won’t be able to comprehend the context of how entities are connected and what they mean; specifically, a machine might provide a false outcome if prompted for a decision.
Imagine that you want to optimize your supply chain using machine learning. But what does it mean to 'optimize the supply chain'? What key factors could we optimize, and can you equally optimize the process, product, and supplier?
With the help of relevant domain experts, you can explicitly model these scenarios and build a semantic knowledge graph that can capture this knowledge in a machine-interpretable way. Again, this is where the W3C semantic Web stack stands out, as it offers OWL and SHACL to help in this process. This layer's machine-interpretability makes interoperability and reusability across disparate systems possible, enabling smooth integration of data for various systems or use cases.
Below is a picture to highlight the model for this use case. We can now infer information from this example and reason further knowledge from this model and the integrated data.

The Semantic (Ontology) Layer
Similar to the vocabulary layer, it’s possible to leverage and extend the knowledge captured in public ontologies such as schema.org, FOAF, FIBO, and many others to extend and enrich your semantic model in the semantic layer.
Additionally, metaphactory can explicitly interlink vocabularies to ontologies (by restricting a class to an entire vocabulary, collection or sub-tree within a vocabulary), which has several benefits, including the ability to leverage controlled vocabularies in model-driven search and authoring interfaces, thus allowing end users to formulate and iteratively refine their information needs based on an agreed-upon terminology. Another benefit is that this interlinking enables AI applications to structure identified terms into classes, which helps these applications gain more comprehension and accurate interpretation of the relations between terms, resulting in an overall more sophisticated understanding of the data. As this previous blog post discusses, it additionally simplifies governance for the individual assets since vocabularies can be maintained outside of the ontology and help ensure data quality.
Unlock the full potential of your data!
Now that you know what a semantic knowledge graph is and how it works, you know that endless possibilities are at your fingertips—it’s a powerful solution for knowledge democratization, sophisiticated analysis and knowledge discovery.
metaphactory is a flexible enterprise knowledge graph platform that transforms your data into consumable, contextual & actionable knowledge and drives continuous decision intelligence. Get end-to-end support from friendly experts who will guide you on your semantic journey, from modeling your data to building custom applications that suit your needs.
Get a free 4-week trial of metaphactory
If you want to try our semantic knowledge modeling, register for our free self-guided tutorial and get a four-week trial! You’ll receive access to helpful videos and hands-on exercises, as well as the opportunity to practice using your data.
Stay tuned for the next article in this series, where we delve into the need for knowledge graphs in machine learning, explore prevalent use cases, and uncover exciting potential applications.

