
In my previous blog post on building Knowledge Graph-driven, FAIR Data platforms I discussed the importance of data and data-driven decisions, processes and tools in accelerating digital transformation. Knowledge Graphs have revolutionized the way data can be accessed and used, and have helped enterprises overcome the challenges posed by distributed silos where information is available to limited audiences, in heterogeneous formats, and represented according to different models. They have led to great advances in terms of data integration, interoperability and accessibility, and have allowed companies to tap into the full potential of their data assets and transform data into valuable and actionable knowledge.
With metaphactory, our customers have been able to rapidly build Knowledge Graph-based applications enabling them to focus on business outcomes, reduce development efforts and quickly produce results that matter:
- Customers in Life Sciences & Pharma have been able to fast-track drug development and drug repurposing.
- Customers in Engineering & Manufacturing have established smart manufacturing processes and have sped up research, documentation processes and industrial configuration management.
- Customers in Government and Cultural Heritage organizations have streamlined data curation and digital publishing processes, making cultural heritage content intuitively available to the public.
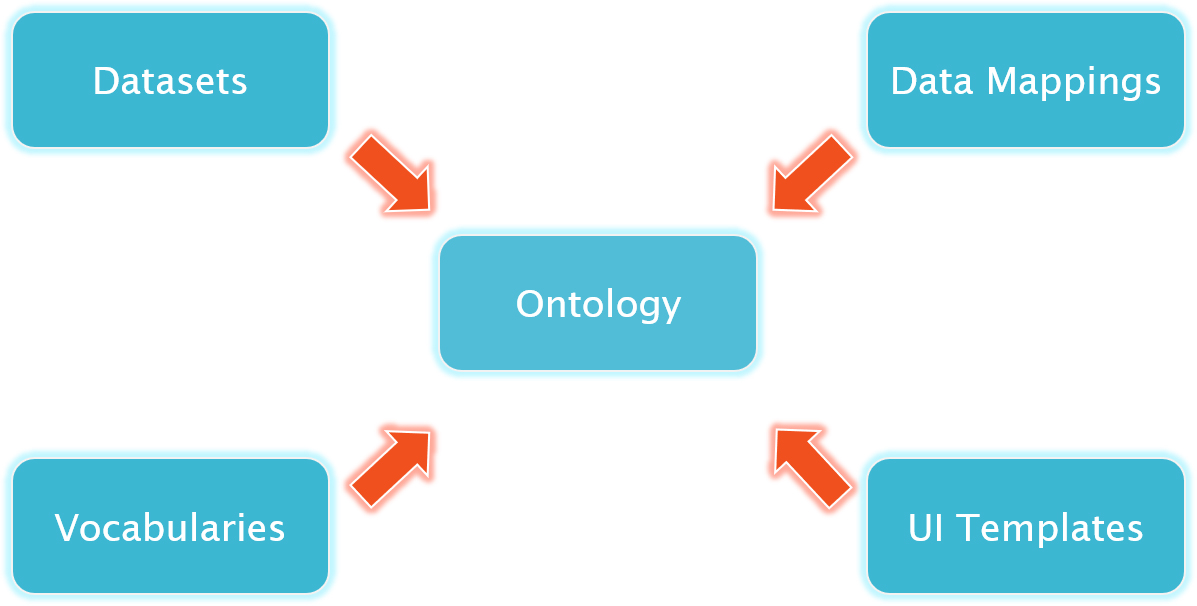
All of these applications utilize a semantic data model to not only describe the domain, but also drive data integration, tie in term vocabularies, or derive UI templates to create a model-driven user interface. Such a semantic data model is called an ontology. According to Gartner, "Ontologies are structural frameworks for organizing information and are used as knowledge representation. Ontology management supports and expands data modeling methodologies to exploit the business value locked up in information silos."
This blog post introduces metaphactory's visual ontology editor - released just today as part of metaphactory 4.0 - which transforms the creation of Knowledge Graphs into a streamlined, end-to-end process where all relevant stakeholders are equally involved.
What exactly is an ontology?
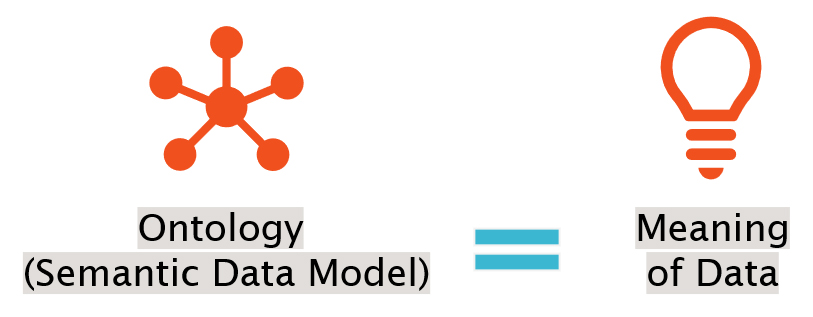
Ontologies are semantic data models that define the types of entities that exist in your domain and the properties that can be used to describe them. An ontology combines a representation, formal naming and definition of the elements (such as classes and relations) that define the domain of discourse.
An example ontology for the Life Sciences domain can be seen here. It combines relevant classes and relations from various disciplines of science (like genomics, proteomics and transcriptomics) and, therefore, also various data sources, into one consistent definition of the domain to support Bioinformaticians and molecular biologists in their daily work. It does not model the individual genes or proteins, but the concept of a gene or protein and how these relate to each other, to help us understand molecular biology and drug interaction with proteins and genes.

Note how an ontology models the business meaning of the data, applying terms and relationships that are used and understood by everyone involved in producing and consuming the data and derived knowledge. This approach builds on an open standard (W3C Standards: OWL and SHACL) ensuring interoperability and reusability down the road, while creating a common understanding of the data, of how and why it was integrated, and of how to correctly consume and utilize it.
Surprisingly, the process of building an ontology is still a complex task requiring the involvement and support of seasoned knowledge graph experts. More specifically, most ontology modeling tools target the ontology engineer, thus excluding domain experts and common business users from this process.
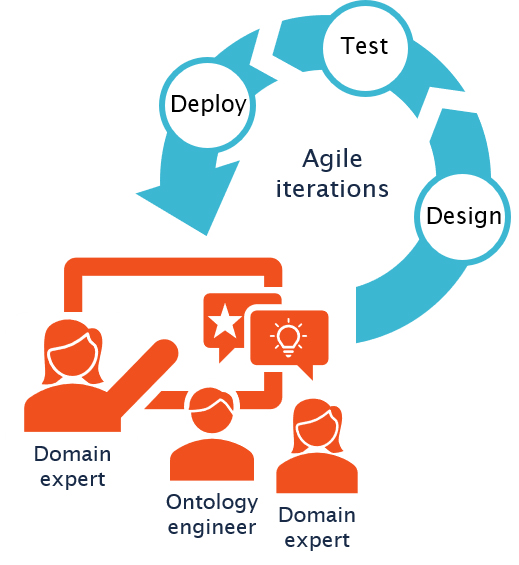
Therefore, what we usually see in organizations is a process as depicted in the diagram below, where a domain expert tries to communicate their domain model using whiteboard drawings, slides or extensive textual descriptions. An ontology engineer then translates this information, based on their understanding, into an ontology, which to a domain expert will look like code. The ontology engineer and domain expert now face the challenge of having to exchange feedback and ideas based on completely isolated representations of this model, and must eventually get to a common understanding of how to correctly model the domain.

Commonly, this is an iterative process where iterations can become lengthy and complex given that there are no tools available that really address and support everyone involved.
Ontology modeling in metaphactory
We have identified this as a major gap that considerably hinders Knowledge Graph adoption within the enterprise and have therefore expanded our metaphactory platform with a visual ontology editor specifically directed at the domain expert and business user.
This approach to knowledge modeling does not only significantly accelerate the modeling process, but also improves the quality of models and ensures early buy-in from the relevant stakeholders who are later expected to contribute data to or consume data from the Knowledge Graph.
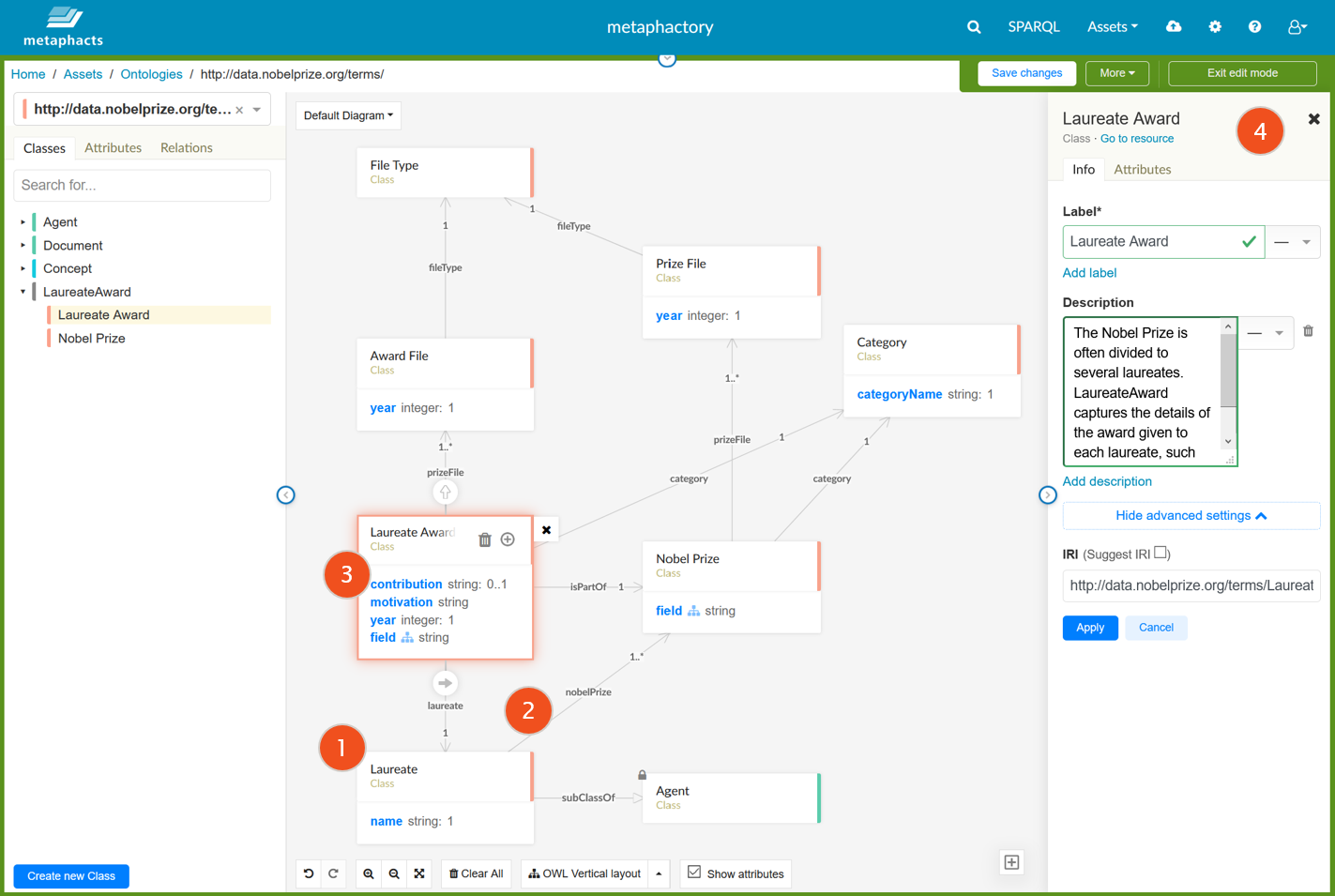
metaphactory’s visual ontology editor follows four simple steps throughout which domain experts, business users and ontology engineers can seamlessly contribute to the ontology engineering process:
- Creation of classes: Classes are created to represent the core concepts of the domain modelled (in this example, the Nobel Prize dataset) - e.g., a Laureate, which is a subclass of a Person or Agent.
- Definition of relations between classes: Relations depict how classes are connected to each other and can include constraints, such as "a Laureate might have received one or more Nobel Prizes".
- Definition of attributes per class: Attributes define additional information about an instance of a class, e.g., the field of a Nobel Prize. Attributes also include relevant constraints.
- Inclusion of additional metadata: Each class, relation or attribute can now be augmented with additional meta-information and can be assigned correct unique IDs.
The resulting ontology follows the open W3C Standards OWL and SHACL and implements best practices we have seen in hundreds of projects over the last years.
metaphactory takes a broader approach on the topic of Knowledge Graph asset management, also providing collaboration features, versioning (see screenshot below), and support for validation of datasets against ontologies.

This allows organizations to implement an agile, iterative process in which all stakeholders can work together to define and continuously improve Knowledge Graphs.
The result is a completely new approach to knowledge management which empowers users to contribute and which also results in quicker and more satisfying results for all stakeholders involved. Ontologies are just the first step here and we will further extend this to vocabularies, data catalogs, mappings and other Knowledge Graph assets.
How can I build on this ontology?
Now that we have a consistent and agreed upon Knowledge Graph model, we can use it to
- connect mappings to load data;
- validate different datasets against the model and find inconsistencies in both the data and the model;
- tie vocabularies into the model to apply common terms throughout all end-user applications, and
- derive the actual end-user application following metaphactory’s low-code application development approach.
metaphactory’s low-code approach enables organizations to extend the idea behind knowledge modeling to application building, where domain users can participate in the process and continuously refine an application built using parameterizable components. These components can be configured and parameterized using the defined models and the open query language of the Knowledge Graph (SPARQL).
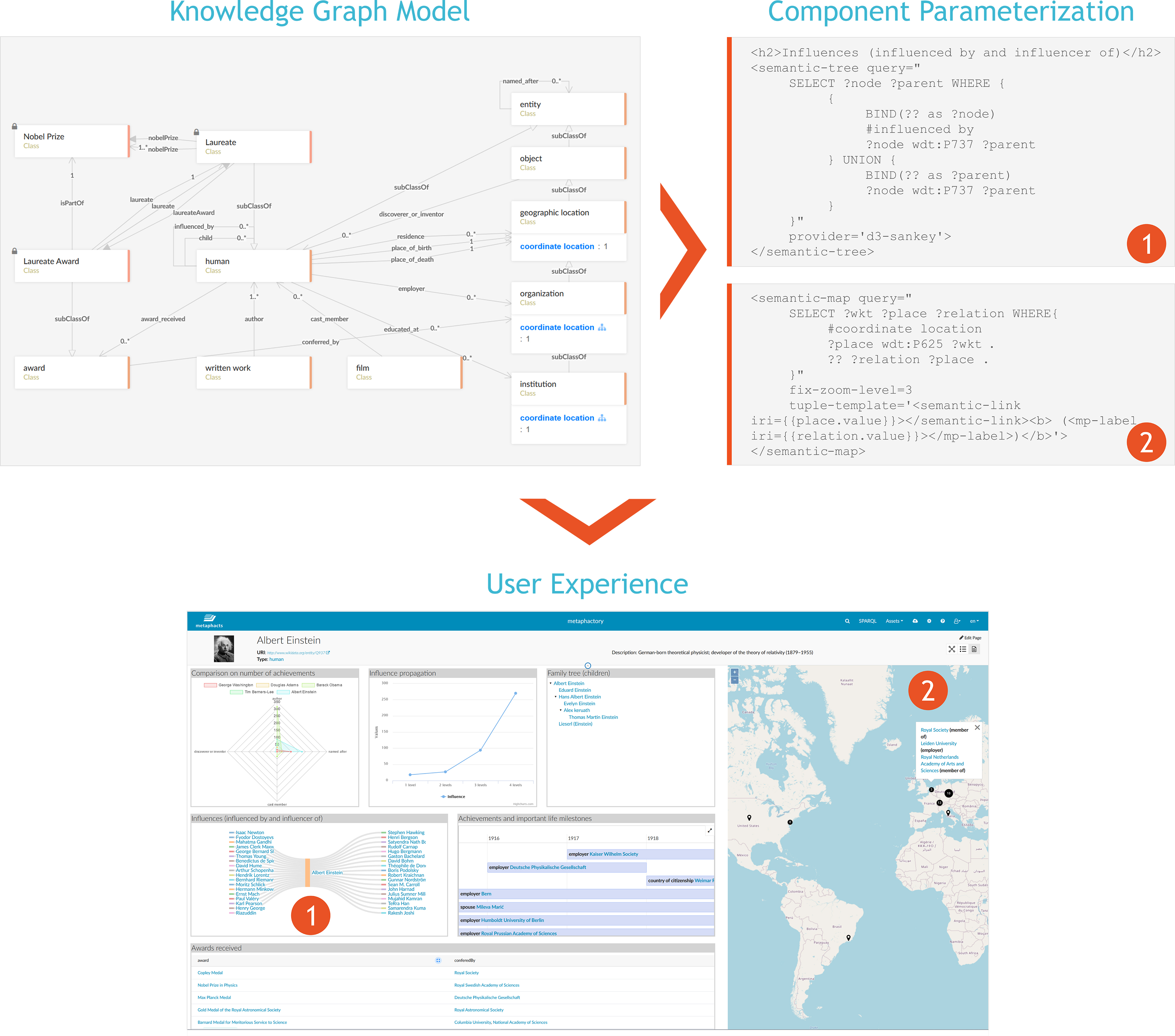
Below you can see an example where we extended the previously introduced Nobel Prize ontology with a new more generic model describing people and their relationships. The diagram also highlights how the concepts and relations in the ontology are used to build a user interface in metaphactory. We included detailed configuration examples for two components in the user interface:
- A sankey diagram which highlights how one person - in this case, Albert Einstein - influenced and was influenced by other persons.
- An interactive map which displays locations related to important events in this person's life.
As the ontology evolves and new datasets are connected, the user experience will automatically update to reflect these changes in the model and in the data.
By transforming existing data into knowledge and then allowing this knowledge to drive end-user facing applications, this process helps enterprises drive innovation. And all of this is achieved in an iterative manner, is driven by knowledge graphs, and is built on W3C standards.
That's cool! How can I try it?
You can get started with metaphactory today using our 14-day free trial. And, of course, don't hesitate to reach out if you want to learn more about how implementing metaphactory and following our approach can also accelerate your knowledge management initiatives and bring you from idea to production in just one month.
Make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.


