
Timely access to consumable, contextual, and actionable knowledge is crucial for any step in the decision-making process and the key enabler of decision intelligence. However, decision makers and decision support systems are still faced with the everlasting challenge that data relevant to and required for addressing their specific information needs is stored in distributed and database- or application-specific silos.
Overcoming data access challenges
Data silos hamper data access on various levels:
- Data is not accessible. Different storage systems impose various physical access barriers (proprietary protocols, drivers, query languages, or APIs).
- Data is not discoverable. Often, dataset metadata - such as descriptive data and governance metadata including provenance or lineage information - is simply not available, and, if any such metadata exists, it is stored separately and is not accessible or interpretable on its own.
- Data is not interpretable. As the data is accessed outside of its application context, it becomes decoupled from its creation, usage, and lifecycle context. Entity Relationship (ER) or Unified Modeling Language (UML) diagrams are rarely available and if they are, they’re not accessible, are stored elsewhere, or are outdated, and are lacking explicit and machine-readable semantics.
In the last decade, data lakes have been advocated to lower physical data access barriers, however, often requiring additional data cataloging systems for making the data findable and traceable through additional metadata management functionality.
Data catalogs are a key piece of the puzzle
Data catalogs have proven to be great for storing and managing such additional context information about available datasets and data sources. However, they often lead to yet another data silo: The metadata about the datasets is captured in proprietary formats and only accessible through custom made interfaces or query languages, while being stored separately from the data itself.
In addition, data consumers - both humans and machines - are still faced with the challenge of interpreting data from disparate data sources. While traditional data cataloging systems are attempting to solve this challenge - for example, by providing additional functionality to build and maintain business glossaries - they often lead to yet another silo where the knowledge is stored and maintained separately and distant from the data itself.
Knowledge graphs support data in context and drive modern data fabrics
Knowledge graphs drive modern data fabrics, enabling frictionless access to and sharing of data. In fact, according to Gartner1, one of the most important components of a data fabric is a composable and highly emergent knowledge graph that reflects everything that happens to your data. The knowledge graph is the key instrument to integrate the data, to provide a unified view over the data, to access the data, and to interact with and understand the data.
In the end, this enables true knowledge democratization by connecting knowledge modeling, knowledge description, knowledge generation, and knowledge consumption under one umbrella. This is because semantic knowledge graphs allow to integrate various meta-layers across various dimensions in a single graph, based on an open and standardized technology stack:
- Dataset descriptions (or data catalogs) based on open and extensible W3C standards (e.g., DCAT) to make the data discoverable, accessible, and traceable.
- Data models in the form of ontologies (OWL and SHACL) and shared terminology (SKOS).
- The data itself or virtualized access thereto.
Data catalogs are clearly a core building block of such an architecture, as they connect the available data assets with the knowledge graph. In this approach, the data catalog is represented as a knowledge graph itself, it is semantically described with descriptive metadata and access metadata, it is interlinked with other parts of the knowledge graph - such as ontologies and vocabularies, and it is embedded into and connected with data assets, thus providing a unified access layer for the end user, with traceable and explainable connections down to original data sources.
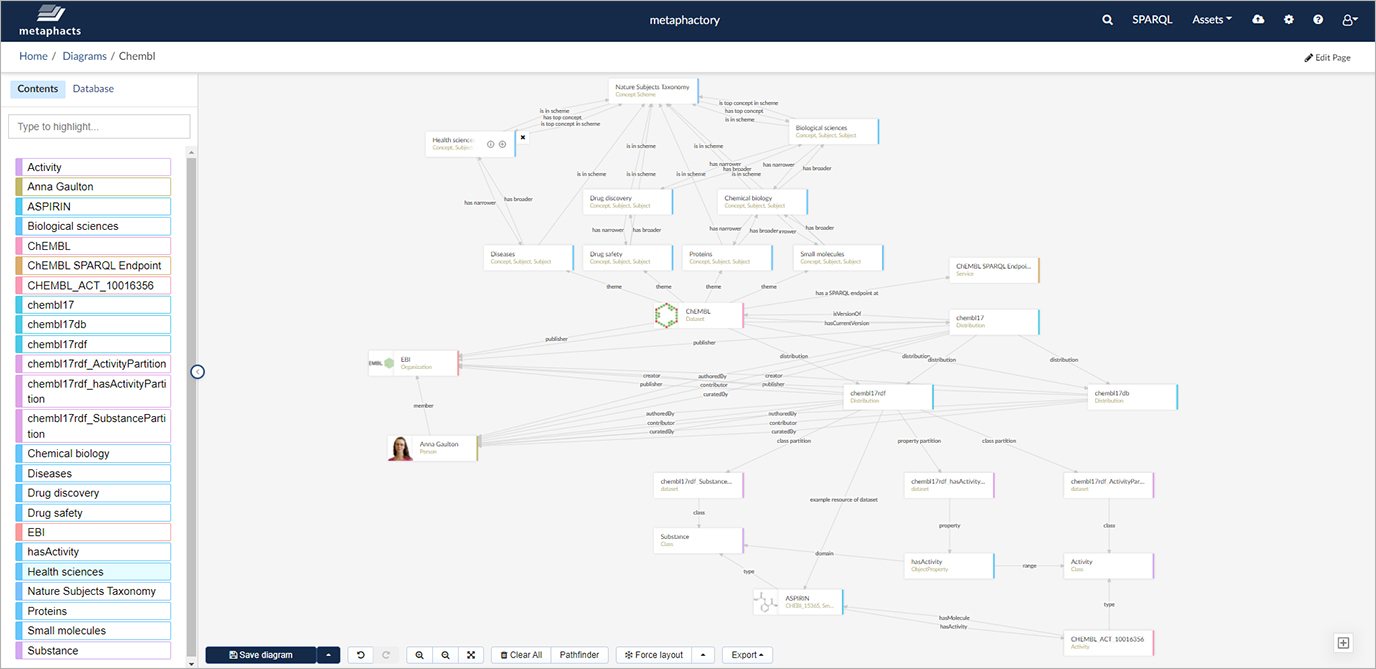
As an example, in the screenshot below we see a specific dataset, ChEMBL, as an instance in the knowledge graph and we can quickly identify descriptive metadata about this dataset from the graph, e.g., license information. We also see publisher information and fine-grained author information down to individual contributors and their roles and we find out that the dataset is accessible as a SPARQL endpoint and that the data is distributed in other forms and versions.
Beyond that, connecting information about the ChEMBL dataset to the knowledge graph reveals additional information and relationships to other assets in the graph:
- The thematic focus of the dataset is described through relations with concepts from a SKOS-based vocabulary (in this case the Nature Subjects Taxonomy) which is also managed as part of the knowledge graph.
- The data in the dataset is described by an ontology also managed as part of the knowledge graph; for example, we see the classes Substance and Activity and how they are related through an object property.
- The actual instance data from the dataset is linked to all other assets in the graph and their metadata. Here, we see that the instance Aspirin comes from the ChEMBL dataset and is an instance of the class Substance modeled with the ontology in the graph.
The key differentiator of the knowledge graph approach compared to system centric solutions is that the metadata and data models can travel with data and make a truly connected graph: Humans and machines (AI/ML algorithms) can consume data in context as the data is directly linked to the models and dataset description, which are based on open standards, are shareable, and can even be queried all at once through a single, semantic query language.
Experiencing data in context with metaphactory
With the metaphactory 4.4 release released in December 2021, the platform supports truly connected knowledge graphs and makes dataset metadata itself an integral part of the graph. Based on open standards (e.g., DCAT, Dublin Core) which interplay well with other relevant standards (e.g., OWL, SHACL, SKOS), these new capabilities allow knowledge graph engineers to easily create, manage, or import existing dataset metadata at integration time. This ultimately also eases knowledge graph maintenance since dataset context information is integrated into the lifecycle process right from the beginning.

Once the dataset metadata is created, it will be shown in the catalog along with other dataset descriptions:
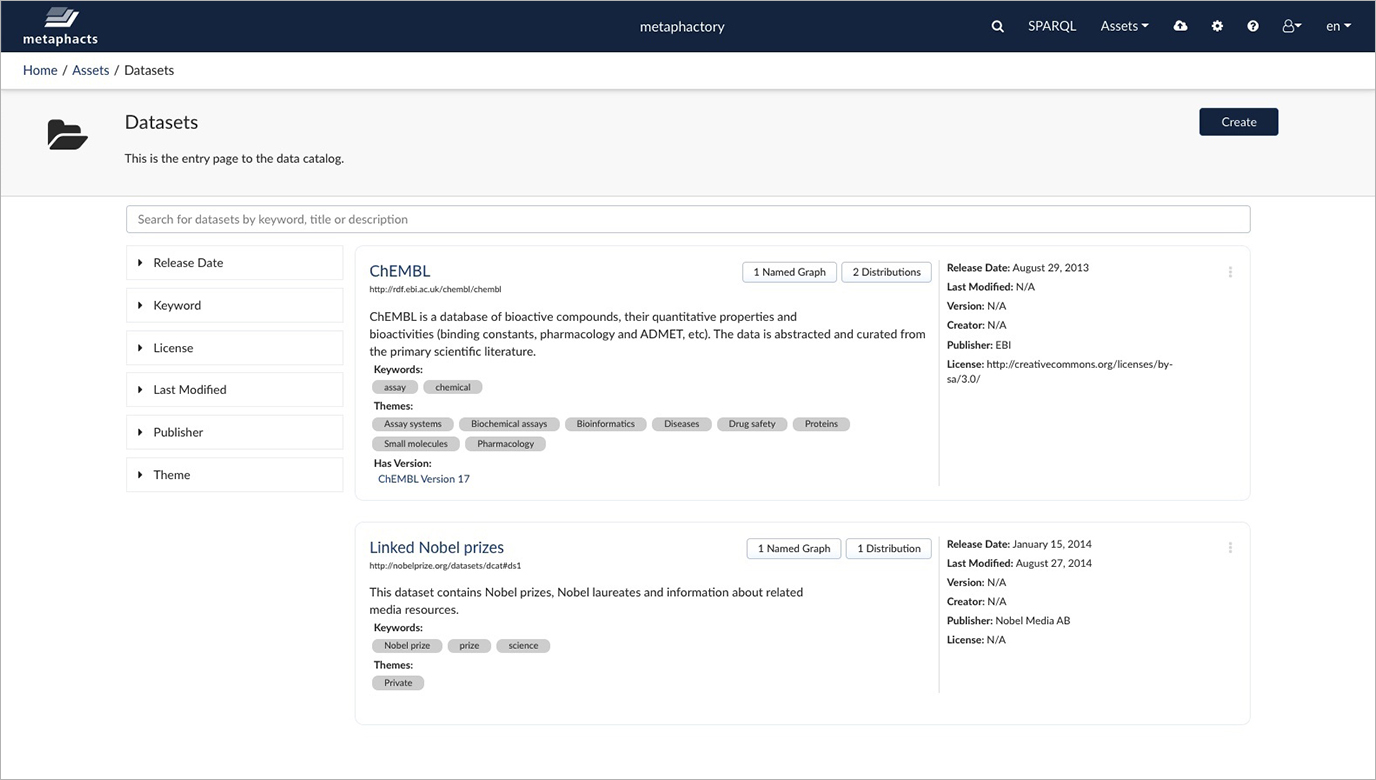
These dataset descriptions can be linked to datasets stored, for example, as named graphs:

Exposed in search interfaces, knowledge panels, and custom dashboards, the dataset context information becomes immediately accessible to end users and domain experts (such as data stewards, data scientists, researchers, biologists, bioinformaticians, chemists, engineers, service managers, etc.) when interacting with instance data. The screenshots below show how an end user looking at the instance Aspirin will be able to understand which source this data comes from, who it was published by, and when it was published:
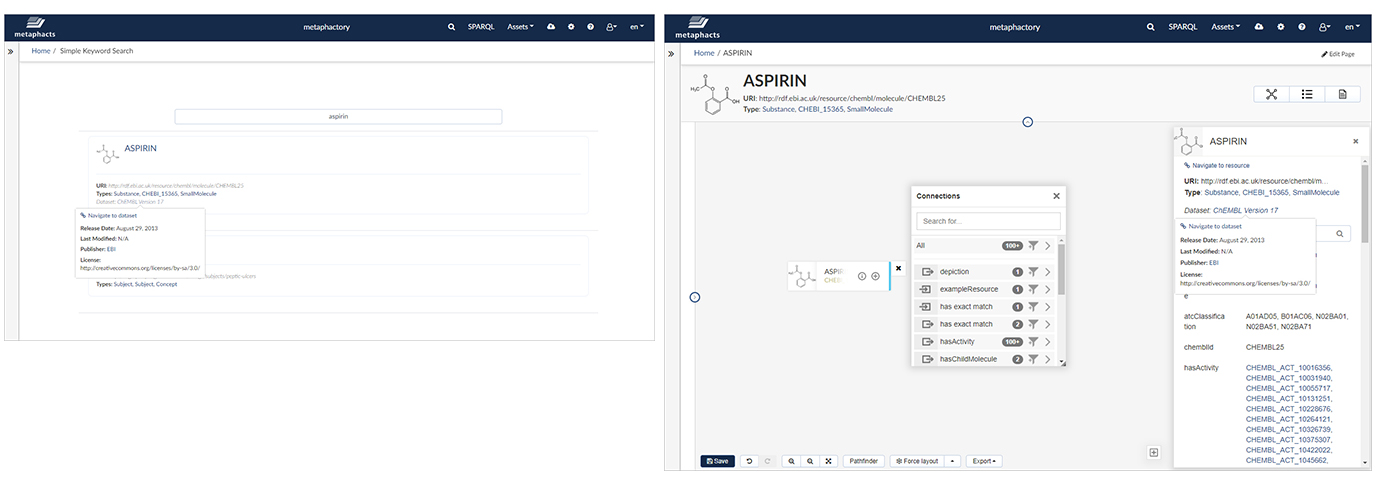
Moreover, end users who focus on creating and publishing data are supported by metaphactory in capturing and curating the metadata, in annotating their datasets, and in linking them with instance data.
Important to note is that datasets do not necessarily need to be created or maintained within metaphactory. As the platform is based on open standards, data providers can provide the metadata when integrating or injecting the instance data. So you can build on the data assets that you already have available - whether they are stored in RDF graph databases or other formats - and which you have catalogued using existing data cataloging tools. You may try this on your own, for example, by importing a DCAT dataset metadata from a public source. For instance, this dataset published by the German government, provides contact and location information for the schools in the state of Schleswig-Holstein.
This sounds cool! How can I try it myself?
To try the new data cataloging functionalities released with metaphactory 4.4. and build your connected knowledge graph, you can get started with metaphactory today using our 14-day free trial. Don't hesitate to reach out if you want to learn more about how these capabilities can be leveraged for your use case.
Make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.
Footnotes
1How to Activate Metadata to Enable a ComposableData Fabric Published by Mark Beyer & Ehtisham Zaidi

