
This blog post is co-authored by Felix Engel and Stefan Schlager. Felix and Stefan work for the department of Biological Anthropology at the University of Freiburg where they lead the development of AnthroGraph – an application that researchers can use to model anthropological data as knowledge graphs and intuitively explore, visualize and find information. In this guest post for the metaphacts blog, they explain how metaphactory was used as the development framework for AnthroGraph and how the resulting application can support the standardization of research data and the creation of reliable, curated and reusable collections of osteological research, ultimately allowing researchers to collaborate across disciplines and perform large-scale analyses.
Osteology – Why biological anthropologists look at human bones
Living populations show the diversity of modern humans around the world. This large biological and cultural variability is a result of our species' adaptation to diverse natural and cultural settings. Biological anthropologists study human biology on the background of humankind’s evolution and cultural history and document how evolutionary processes have shaped the way we live and experience the world.
To understand the transformations undergone by our species, biological anthropologists perform research into geographic, ecological and social factors that have affected humans during the past centuries, millennia and millions of years. For example:
- Early morphological developments towards upright gait, increased brain complexity and dexterity are documented through fossilized human remains.
- Skeletons of humans witnessing later transitions to agriculture and complex settlement types are recovered from burials and other contexts.
- Additional information comes from natural and man-made mummies.
This evidence yields information about the demography of ancient populations, diseases they experienced and challenges in their specific habitats. To learn about these issues, researchers analyze the morphology of human remains as well as the structure and molecular composition of their tissues.
Human skeletal remains are among the prominent materials for biological anthropology, making osteology – the study of skeletal elements – the basis for many anthropological methods and findings from this domain need to be related to research on living populations. As this information explains parts of humankind's current condition, it is also applied in medicine, forensic sciences and industrial design.
All these materials, topics and methods require a full range of highly specialized scientists collaborating in a broad field of research to answer big, far-reaching questions. Many of these approaches are comparatively young and are still being actively developed. Therefore, data models representing research outcomes are highly volatile and prone to frequent redesign.
Early approaches to the management of osteological research data
Collecting life-history information from human skeletal remains commonly requires researchers to evaluate processes of biological development and deterioration. Code books defining developmental steps are published to make such observations comparable and quantifiable. This is essential for assessments across different datasets but is also a prerequisite to control observer errors – a central challenge in osteological research. Conformity of data structures is also necessary for pooling data from various sources and the formation of large databases. Success on these lines will open up an entire new scope of research potentials.
Standardization of osteological data has a long-standing history in biological anthropology. Early research databases were established in the 1960s and coding standards have been published since the 1980s. These projects faced a series of challenges:
- The reliability of osteological observations needed to be quantified in order to guarantee data quality.
- Ongoing improvement of methods rendered datasets outdated.
- Rigid data models required centralized data collection and struggled to adapt to scientific dynamics.
Even today, large collections of reliable and curated osteological research data are hardly existent. Their establishment, however, would unlock vast research potentials. Large-scale analyses allow to trace past living conditions on a broad geographical level and along historical trajectories.
Semantic Research Data Modeling – A new future for osteological data management?
Conventional approaches have failed to address all requirements for research data management in biological anthropology. Data curation in particular has not become a research routine and best practices have not yet been developed. This is partly because existing data standards and databases are too rigid to become adopted by specific projects. Also, integration of osteological data with contextual information is a challenge to many researchers and is often met with makeshift solutions.
Based on these general considerations, in our research project run by the department of Biological Anthropology at the University of Freiburg, we strive to develop a strategy that allows for evolving data standards that are flexible enough to adapt to specific types of investigations. Existing data models need to be extended, merged or otherwise transformed to meet new requirements. At the same time, formerly collected data should be reused wherever possible.
Our research project uses semantic web technologies to model osteological research data as nested knowledge graphs. We have developed an ontology called RDFBones that integrates selected existing ontologies and appropriates them to osteological research in biological anthropology. Because it is based on open standards (RDF and OWL), this core ontology can be extended by researchers and projects with additional ontologies covering data produced by their specific research designs. The common use of the core ontology and the fact that extensions share elements among each other help achieve data compatibility.
Bringing data modeling to anthropologists
So semantic technologies can help to bring substantial improvement to research data management in biological anthropology. But most anthropologists are not aware of the data structures they produce and are often reluctant to endorse new approaches to improve their data output.
To demonstrate the potential of semantic technologies for research, we want to enable osteologists to model the data they collect as knowledge graphs while using work environments they are familiar with. To this end, we are developing the database application AnthroGraph that automatically generates comprehensive graphs from conventional data entry forms. We want researchers to benefit from the advantage of querying and visualizing these graphs – and ultimately reuse collected data – without having to learn semantic technologies themselves.
We have chosen metaphactory as the development framework for AnthroGraph for various reasons. In metaphactory, forms for data entry and representation are mostly configured through SPARQL queries – the query language for RDF – and require little knowledge of IT technologies (See Fig. 1). Most of the required skills are also needed for querying data for analysis and, therefore, lie within the scope of scientific analysts. As a low-code platform, metaphactory offers visual wizards for generating form and search interfaces, so even researchers without prior knowledge of SPARQL can use metaphactory to create infrastructures for their peers.
Moreover, we appreciate the metaphactory app mechanism as a basis for providing specialized tools that can be easily deployed by institutions and research projects. metaphactory also provides out-of-the-box visual tools for intuitively exploring, querying and understanding knowledge graphs that underlie data forms and provide an excellent environment for data queries (See Fig. 2 and 3).
Currently, AnthroGraph is used for the development of data entry forms for an ongoing bioarcheological project – the Phaleron Bioarcheological Project – and in collaboration with biological anthropologists there. Our partners provide a first use case for AnthroGraph – described in more detail in the next section – and deliver feedback for the application. However, we expect AnthroGraph to serve numerous other research use cases in the future. Future applications will likely entail various scenarios where researchers will engage with the software in different roles and with different user needs, according to their individual skills and positions within research projects.
It would be desirable for researchers to acquire some basic knowledge of data modeling in order to describe their proposed research methods as RDFBones ontology extensions. Extensions provide precise specifications of research practices and resulting data structures that are based on open modeling and validation standards. Such resources are the result of scientific work and should be published in appropriate publication outlets. Essential ontology extensions that are likely to be frequently reused should be improved through continuous development and have versioned releases. In this capacity, researchers function as knowledge graph editors, providing resources that can be integrated by peer scientists into their work in various ways.
It cannot be assumed, however, that all researchers acquire knowledge in research data modeling in the short term. Many osteologists will rely on AnthroGraph to work in an environment they are accustomed with. There is an immediate need for application engineers to create these environments from RDFBones extensions and provide them to end users. Such apps may range from self-made solutions for PhD projects to polished versions commissioned by institutions.
The AnthroGraph metaphactory app provides a framework within which several specific-purpose apps can operate simultaneously. This structure is intended to enable research institutions to provide custom work environments to various staff members, work groups and research projects. It is the basis for a federated system of independently managed databases that is constantly diversifying. At the same time, the RDFBones core ontology allows to pool data from all instances in this system for joint research projects.
Positioning AnthroGraph within the community
To validate the approach we've taken with AnthroGraph, we are currently collaborating with the Phaleron Bioarcheological Project (PBP) where an international research team investigates human remains from a large burial site from the classic period in Athens, Greece.
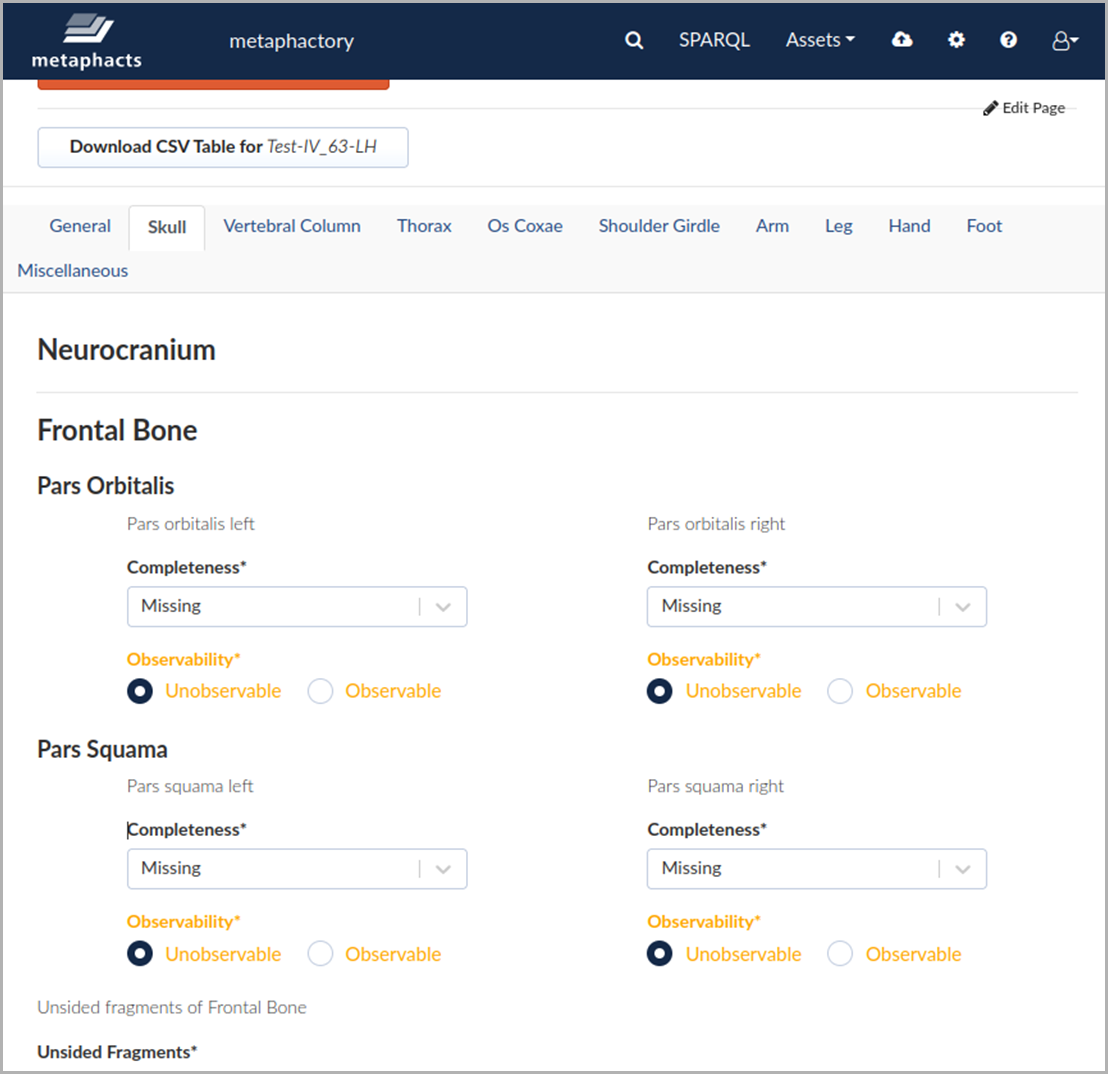
Fig. 1: Form for entering and displaying Skeletal Inventories for the Phaleron Bioarcheological Project

Fig. 2: Graph showing the main structure of the Skeletal Inventory
Have a look at the SPARQL query for this graph »
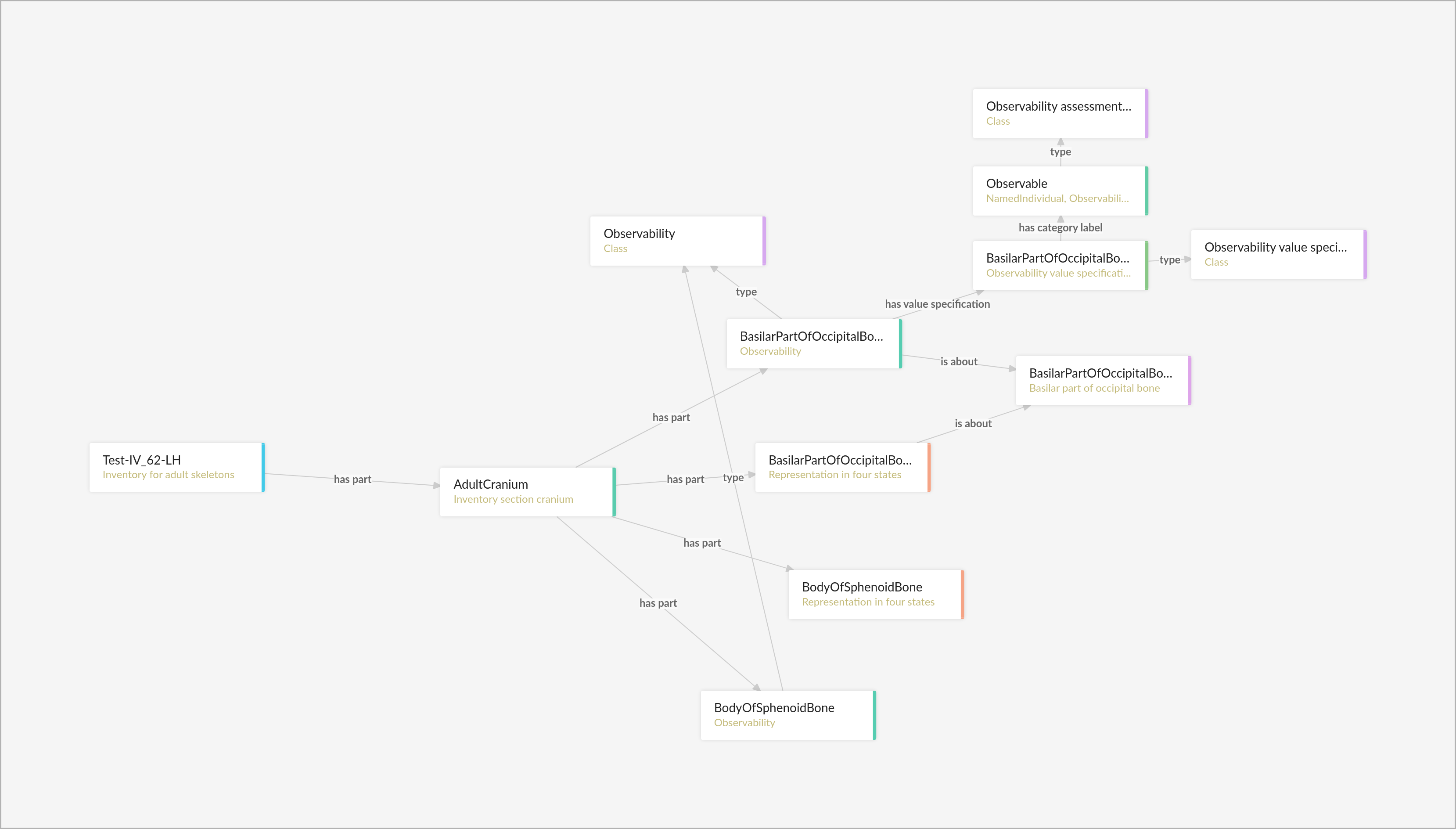
Fig. 3: Subgraph displaying the information recorded in an exemplary single form
As part of our collaboration, we are developing a suite of specific apps modeling the skeletal material and the research based on it. As this is an ongoing project, the data model is developed dynamically while data acquisition continues – another benefit of RDF. It allows to directly assess the consequences that changing the data model has on the modeling of the research further downstream.
A central aspect of working with the Phaleron osteologists are discussions about their data acquisition concept which they have not regarded as a data model in the past. Knowledge graph development raises questions concerning definitions of data fields and their inner linkages. These considerations have already led to considerable improvements of the recording scheme. This shows that data modeling belongs to the research domain and could not be delegated to technicians, which is why providing researchers with tools that ease this task is key.
We intend to establish AnthroGraph as a resource to be collectively developed by the research community. It should bring together individuals with various skills and result in better research data management and a richer data base.
During the remainder of our project, we will engage in additional collaborations with current research endeavors in order to spread research data modeling as a way of thinking about research and research outcomes. This will involve the expansion of AnthroGraph to satisfy a wider range of requirements.
We believe that metaphactory is a suitable framework for this type of software development. A large part of the configuration is done either through visual interfaces or through SPARQL queries, a skill that is worthwhile to obtain for anthropologists, and other open standards. Therefore, large parts of the code can be reused in other research contexts. Metaphactory's rich templating functionality further supports sharing between different applications.
Biological anthropology is a discipline that lives in small organizations scattered across various universities and research institutions. This infrastructure makes it difficult to establish software services that are continuously maintained over large periods of time. The metaphactory app functionality helps to overcome this deficiency as institutions and project groups can revive any app with a fresh software subscription. Collaboration with external researchers is greatly facilitated by the possibility to provide queries as a service.
Where to go from here
Semantic research data modeling has been successfully applied in the life sciences for years. With the technology mature enough and funding agencies currently supporting infrastructure projects, semantic research data modeling can now be established in small disciplines like biological anthropology as well. This process is supported by the flexibility of the Resource Description Framework (RDF), allowing appropriation of resources developed elsewhere to new knowledge domains.
The ultimate task is to develop large bodies of curated and reviewed osteological research data as a basis for large-scale analyses. These need to be built up continuously from the output of ongoing research projects. For now, it is necessary to train researchers in semantic research data modeling so that they can conceptualize and enable these early contributions. AnthroGraph serves as a vehicle for these efforts.
Metaphactory has proven as a valuable tool for automating semantic enrichment of research data from traditional input and for writing, executing and sharing data queries. With more and more ontology editing functionalities being implemented, it can also function as a work environment for researchers to comfortably write their own ontology extensions.
With AnthroGraph and RDFBones we aim to enable researchers to satisfy requirements arising from ongoing research and quickly adapt to new research use cases, instead of dictating fixed – and rigid – solutions. We hope for this approach to change the way researchers think about the knowledge they produce, and the ways in which it is used and shared.
This sounds great, how can I try RDFBones & AnthroGraph?
If you are interested in using RDFBones or AnthroGraph for your own research or for enquiries please contact Stefan Schlager (
Or visit our organisations on GitHub:
How can I try metaphactory?
To try metaphactory for your use case, you can get started today using our 14-day free trial. Don't hesitate to reach out if you want to learn more about how implementing metaphactory and following our approach can accelerate your knowledge management initiatives!
Make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.

