
Many enterprises have identified Knowledge Graphs as the foundation for unlocking the value of their data assets, easing knowledge discovery and surfacing previously unknown insights and relations in their data. But while the benefits of Knowledge Graphs have become clear, the road to implementation has often been long and complex. Success in making these benefits tangible to the actual business users who interact with and rely on this data on a daily basis has required the involvement of seasoned knowledge graph experts.
In this blog post, we provide an introduction into metaphactory's intuitive and interactive wizards which support application engineers in quickly and visually setting up and configuring search and authoring interfaces that cater to specific end-user information needs. The wizards (introduced recently with the metaphactory 4.2 release ) are one of the pillars of metaphactory's low-code approach for building knowledge graph applications. They allow application engineers to focus entirely on translating end-user information needs into intuitive, model-driven interfaces without getting caught up in the technical details of the semantic technologies stack.
Having a Knowledge Graph is not enough
Knowledge Graphs help capture and represent domain-specific knowledge in terms that business users can understand and use for analysis, and in answering critical business questions. The raw data is usually distributed across multiple departments (or even outside the organization) and stored in heterogeneous formats. Building on mature, open standards and FAIR data principles, knowledge graphs do not only connect disparate data points and help drive automation by making data machine-understandable and -interpretable, but also improve data literacy in the organization by transforming data into knowledge that is browsable, searchable and shareable by human users.
So far, so good: through knowledge graphs, actual knowledge is made available to end users. Available, but not readily accessible yet, at least not in an intuitive manner, without an end-user oriented interface that caters to the end users' business needs.
Through its low-code approach, metaphactory allows customers to quickly build intuitive apps for model-driven search, visualization, discovery, exploration and authoring on top of their knowledge graphs. This is accomplished through declarative and customizable templates and a rich set of ready-made Web components.
With the metaphactory 4.2 release, setting up end-user interfaces becomes even easier through no-code, interactive wizards which allow for configuring components in a step-by-step-manner.
Bootstrapping a Knowledge Graph Application with metaphactory
metaphactory's interactive wizards guide application engineers visually through the individual steps of setting up components for business applications. For example, one wizard assists application engineers in configuring a semantic search which can be used by business users to answer detailed information needs.
Because the configuration wizard abstracts over technical details, the application engineer can fully focus on her task of mapping the end-user information needs to the ontology - the backbone data model of any knowledge graph. The application engineer identifies and visually selects classes, relations and attributes from the ontology that are required to capture the end-users' information intent, originally provided to her as natural language queries.
By capturing the end-users' information intent through references to the ontology, the semantics of the data is not hardcoded in the application logic or in the data itself, meaning that the user interface is driven by the ontology.
In the end, the wizard generates a low-code HTML5 component configuration, which can be inserted into the application page. This allows application engineers to quickly get components up and running without the need to write SPARQL queries, understand the particulars of the OWL/SHACL modeling language, or copy-paste lengthy identifiers.
However, to incrementally advance the end-user application in an agile spirit, the configurations can be further tailored through metaphactory's low-code approach, i.e., by refining the component logic through declarative parameters, or the design and layout through HTML and CSS to meet the desired look-and-feel.
As an additional benefit, since the application engineer is setting up components by focusing on the purpose of the end-user interface rather than on implementation details, the process also helps familiarize herself with the terminology of the technology stack and the general approach towards model-driven knowledge graph solutions.
Step-by-step Example
Let's look at a concrete example of how this works.
We'll start by looking at a specific end-user information need. For the purpose of this demonstration, we will work with the Nobel Prize Dataset, a public dataset available as a Semantic Knowledge Graph, i.e., it is published in RDF and described by an OWL ontology. It includes information about all Laureates (Persons, Organizations) who have received a Nobel Prize Award in a certain Category, or a share thereof, ever since the inception of the Nobel Prize 1.
Let's imagine our end users need to look up which Nobel Prize Awards were given in a certain category (e.g., Physics) within a certain time frame. While encoding this information need in a SPARQL query is a rather simple exercise for a knowledge graph expert, it bears a high entry barrier not only for end users but also for application engineers who are not familiar with the semantic technology stack.
In our role as application engineer, we can now use the new wizard functionality available in metaphactory to configure end-user search interfaces without programming and without in-depth knowledge about the stack. In turn, the resulting interface can be used by end users without any technology knowledge at all, to interactively construct and refine queries.
The wizard can be invoked from the standard metaphactory page editor. We do this directly on the page where we later on want to display the search functionality to end users. In this example, we create a new page ":NobelPrizeSearchDashboard:"
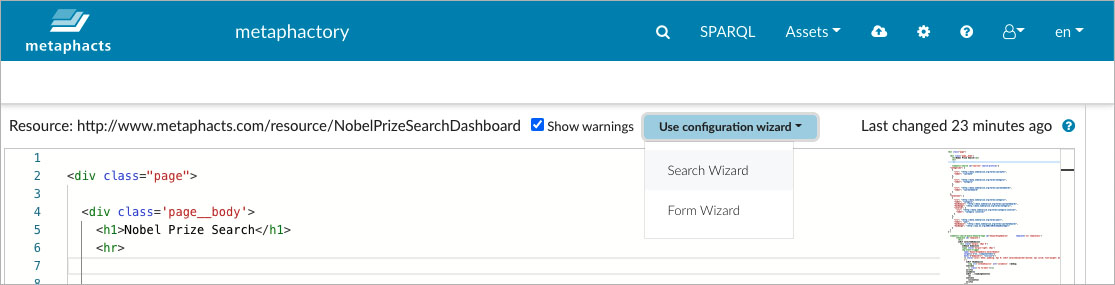
The wizard can be invoked from the standard metaphactory page editor.
Step 1: Selecting the search paradigm
In the initial step of the search wizard, we need to decide what type of search paradigm we want to offer to our end users. To learn more about the various search components available in metaphactory and which information needs each one is best suited for, have a look at this blog post »
In our example, the end users are interested in data pertaining to particular classes of entities (e.g., awards, laureates). Additionally, they need to be able to filter the data by structured metadata (e.g., the year the award was given in, the award category), which can be easily made accessible through faceted filtering. Since the information need expressed by our end users is still rather simple, we decide that the keyword search component featuring type-based disambiguation is sufficient here.

In the initial step of the search wizard, application engineers need to decide what type of search paradigm they want to offer to end users.
Step 2: Selecting relevant classes from the ontology
Once we have selected the search component and specified that we want to enable facets, in the next step we can identify and select the classes relevant for the information need from the ontology. By default, the wizards show all ontologies loaded in the database. This is because, often, multiple ontologies and datasets integrate with eachother and are required to cover information needs across datasets.
In our example, we have loaded the Nobel Prize Ontology 2 (RDF file), the FOAF ontology (RDF file) and the SKOS ontology (RDF file).
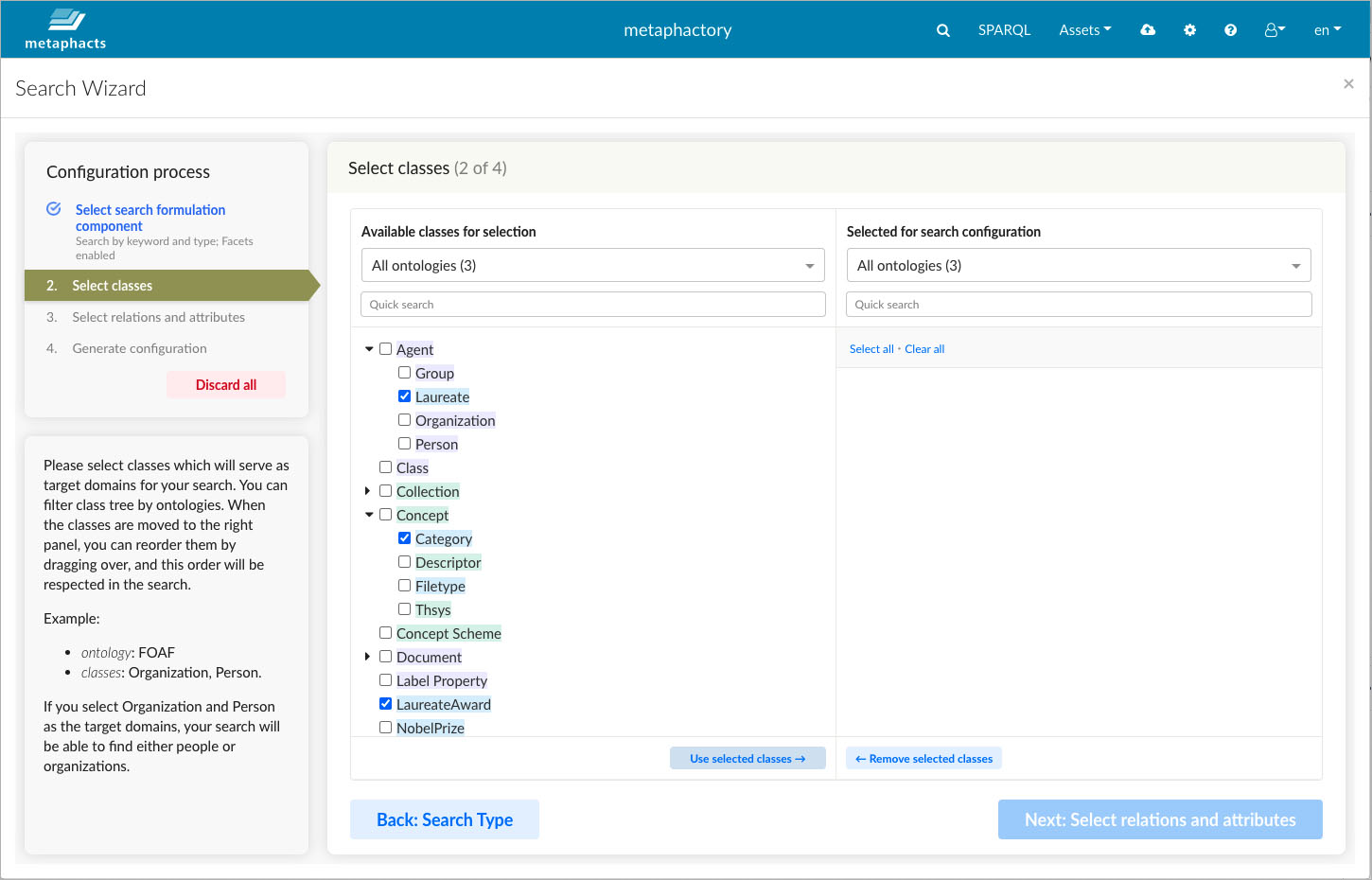
In the second step, application engineers can identify and select the classes relevant for the information need from the ontology.
We can see, for example, that the class "Laureate" in the Nobel Prize Ontology is a subclass of the class "Agent" from the FOAF ontology. (Expanding the Ontology Filter "All Ontologies (3)" will show the color legend and hovering over entries will show their full identifiers as titles).
Here, we decide to select the classes "Laureate", "Laureate Awards" and "Category", as these are the obvious classes mapping to our end users' information need.
For the selected classes, the wizard will check on the existence of instance data within the database. If no data is available for certain classes, end users might not get any results when they choose one of the classes in the search interface.
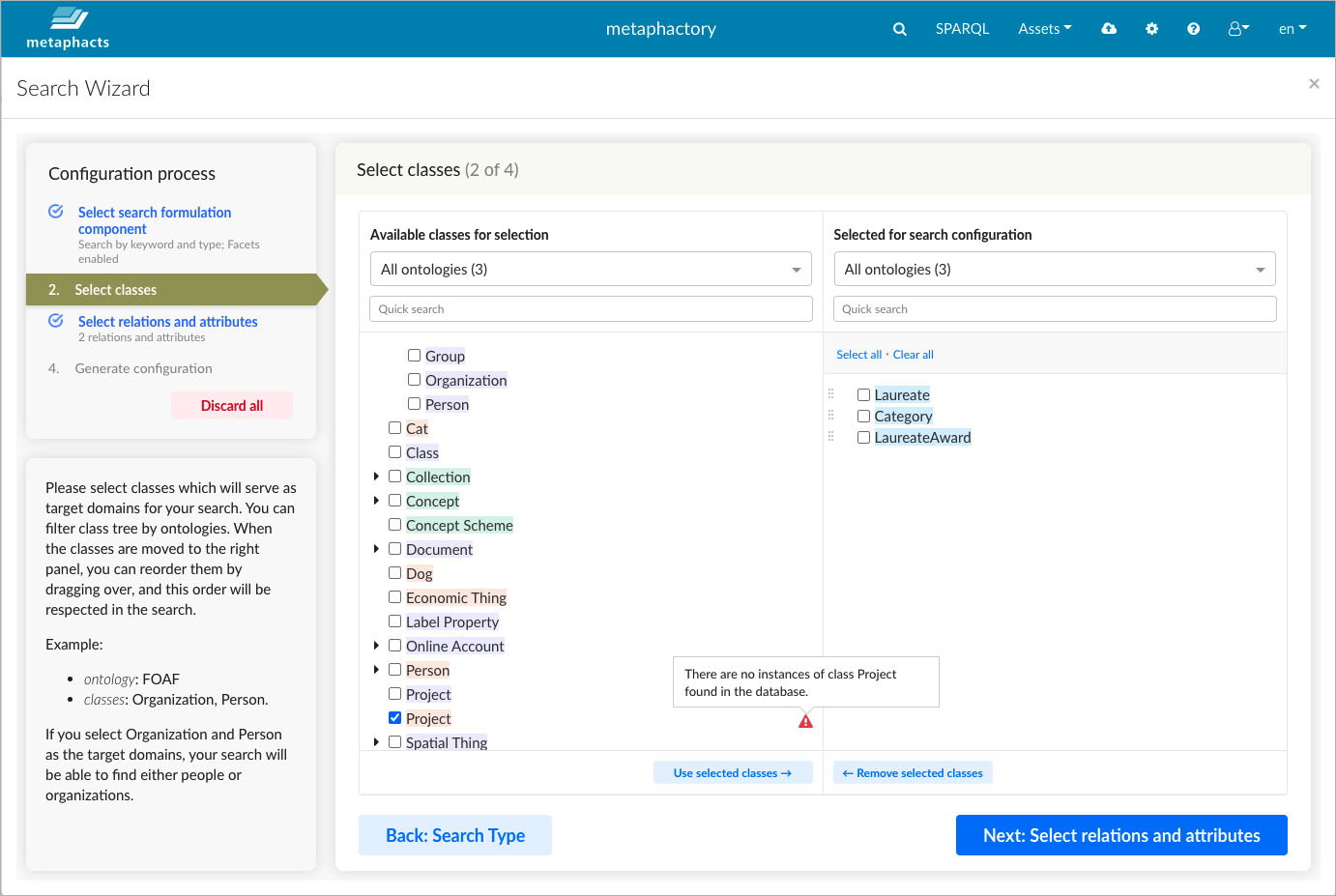
For the selected classes, the wizard will check on the existence of instance data within the database.
Step 3: Selecting relations and attributes
In the next step, we need to select relevant relations and attributes from the ontology. For example, "category" is modelled in the ontology as a relation which holds between the class "Laureate Award" and the class "Category", which, in turn, is a subclass of the class "Concept" from the SKOS ontology. The latter basically states that all values of "Category" are concepts defined in a SKOS vocabulary. The diagram below taken from our visual ontology editor illustrates these relationships 3.

This excerpt of the ontology illustrates the category relation between the class Laureate Award and the class Category.
As application engineers, we may not have in-depth knowledge about the ontology and certain modeling decisions, for example, whether certain aspects are represented as attributes of classes or as relations between instances of classes. That is why, in the wizard, we can select both relations and attributes in the same view and decide class by class which aspects might be relevant to bridge to the end users’ information need.
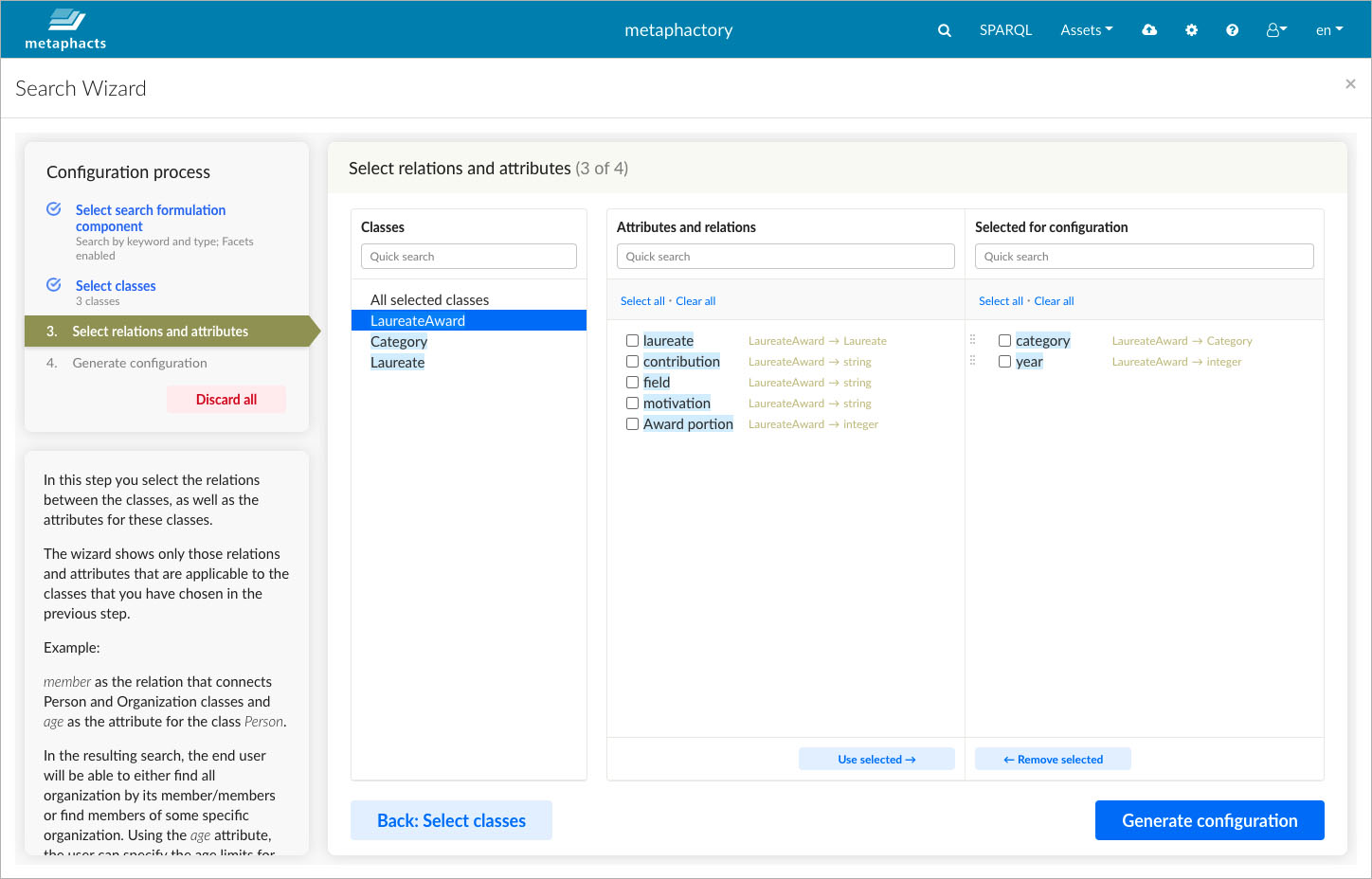
In the third step, application engineers need to select relevant relations and attributes from the ontology.
In our case, we decide to select "category" and "year" as relevant properties and to not include further properties initially. This way, we gain control over what we present to end users and can tailor the end-user interface to specific needs, instead of overloading them with information that they might not need at all.
Step 4: Previewing and testing the configuration
In the final step in the wizard, the configuration code as well as a live preview are generated. The live preview allows us to test the resulting search and refine the configuration by going back in the wizard steps, before finally adding it to the application page.
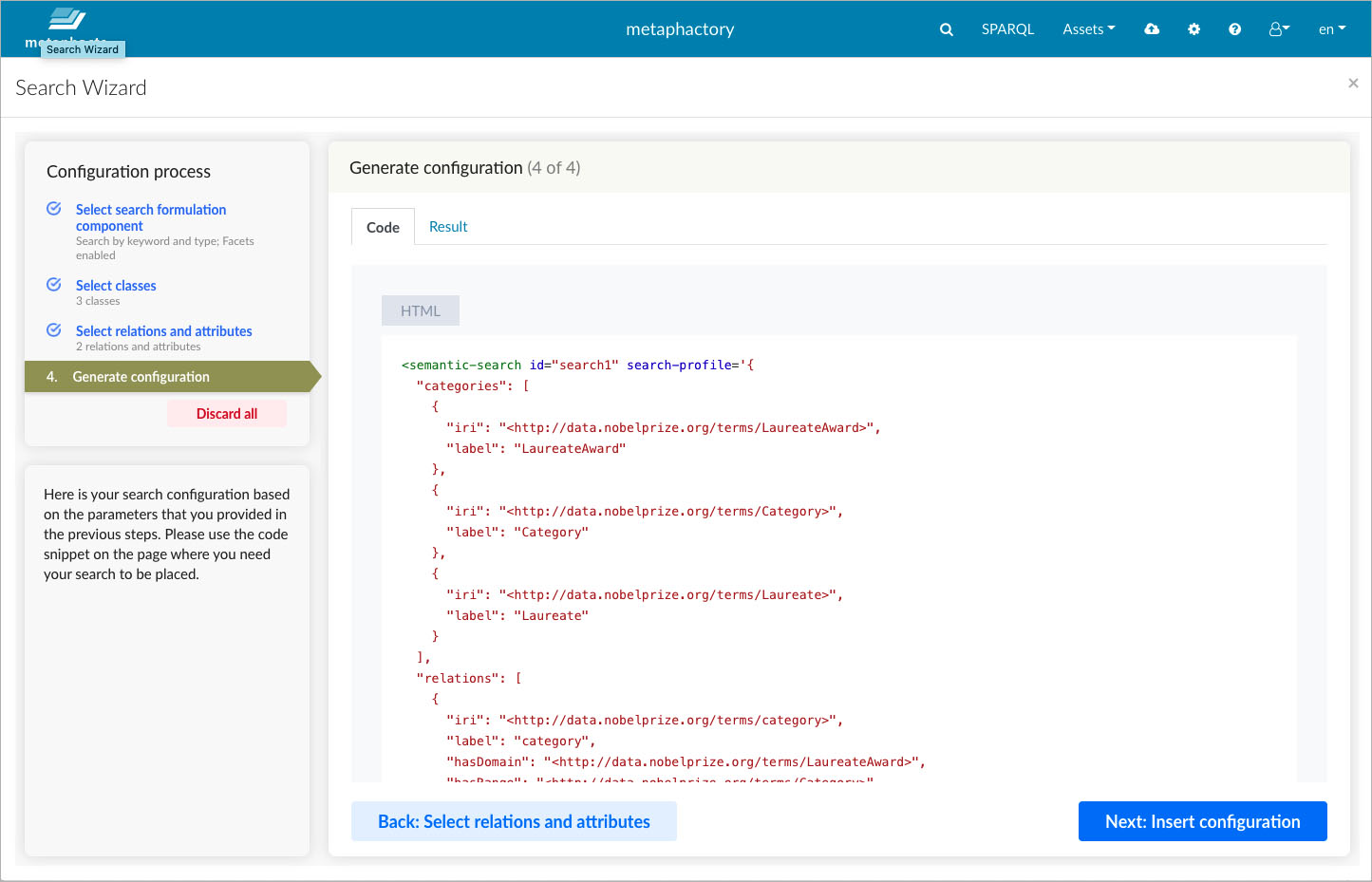
In the final step, the wizard generates the configuration code.
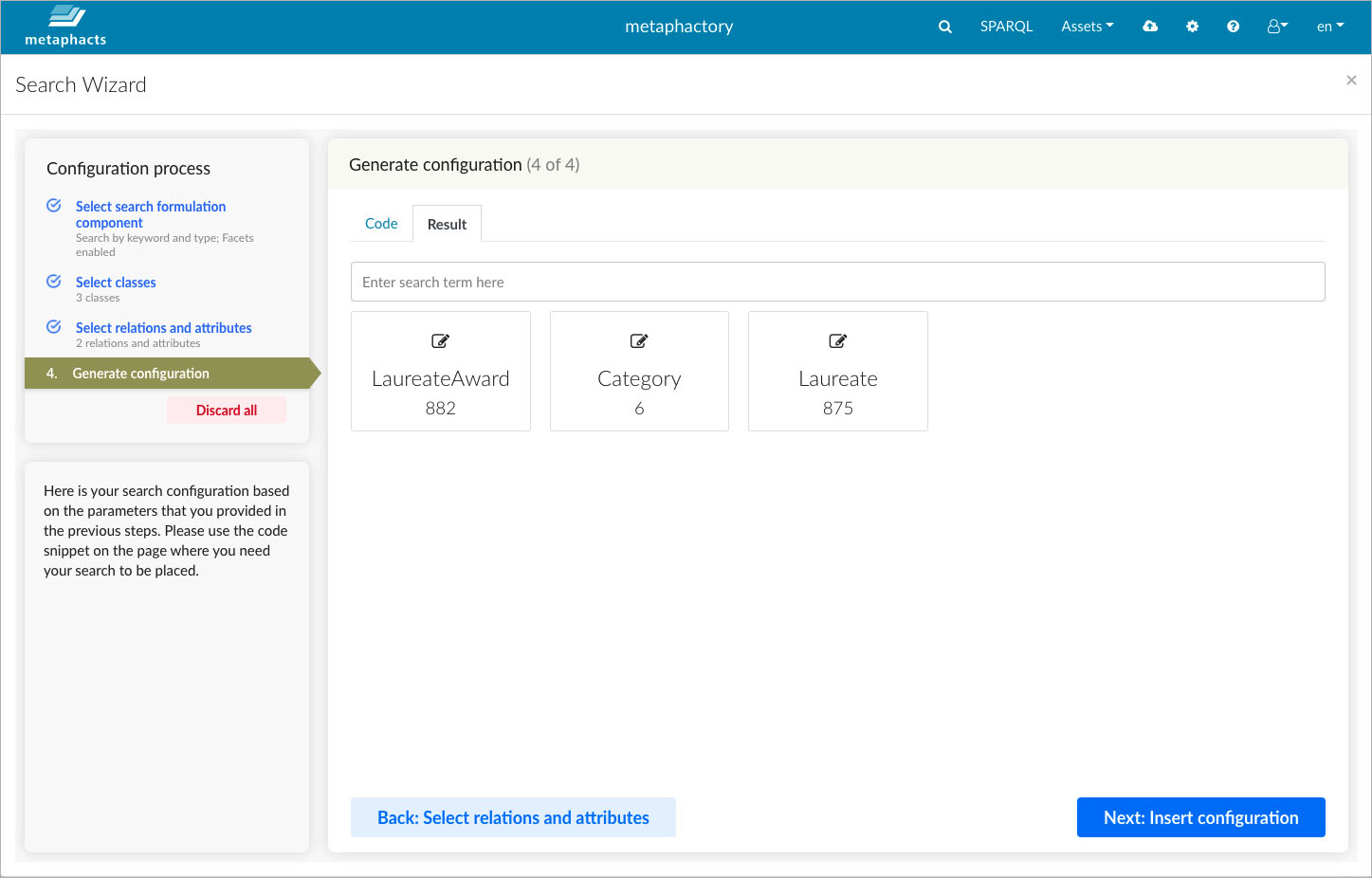
The wizard also generates a live preview of the defined configuration.
Once the configuration code is added to the page, we can gather end-user feedback and start the agile process of incrementally fine-tuning the configuration or presentation. While the wizard helps to quickly bootstrap the basic configuration with no coding involved, we still have the full flexibility to customize, for example, the result presentation with low coding effort, i.e., through a rather simple configuration of HTML elements and respective configuration properties.
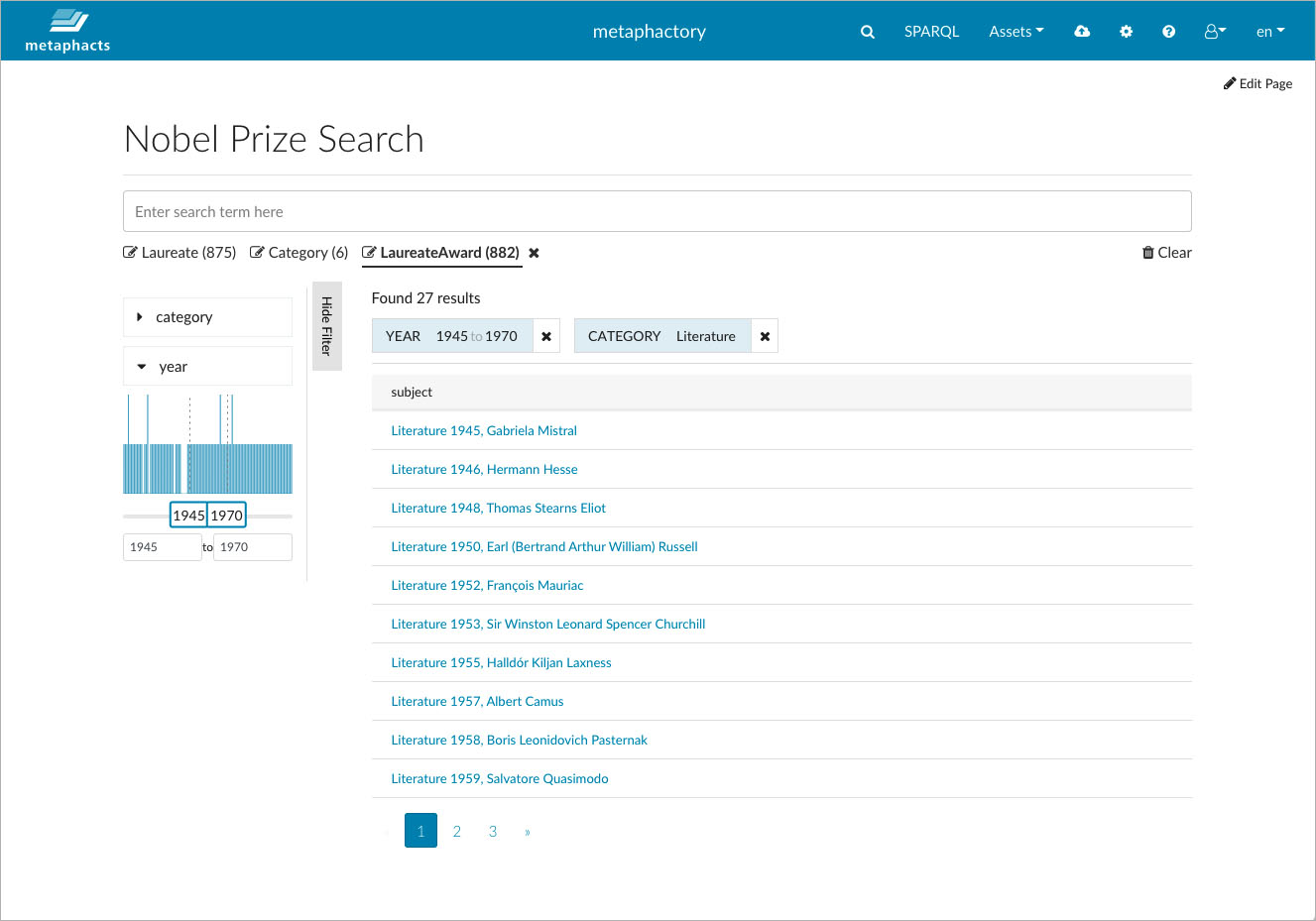
The live preview allows application engineers to test the selected component before publishing it.
That's cool! How can I try metaphactory?
To try out the new metaphactory wizards with your own data, you can get started with metaphactory using our 14-day free trial. If you’d like to reproduce the example in this blog post and try out a different search paradigm or the authoring component, you can download the Nobel Prize dataset here and the Nobel Prize Ontology from our public GIT repository »
And, of course, don’t hesitate to reach out if you want to learn more about implementing metaphactory and make sure to also subscribe to our newsletter or use the RSS feed to stay tuned to further developments at metaphacts.
Footnotes
[1] The snapshot of the dataset linked to this blog post contains data up to 2013 and can be downloaded here. Please note that this public dataset is licensed under Creative Commons Zero (CC0) and free to use as stated by the Terms & Conditions of the Nobel Prize website.
[2] You can find the Nobel Prize Ontology in our public GIT repository »
[3] To learn more about visual ontology modeling with metaphactory, have a look at this blog post »

