 This post has also been published on the AWS Database blog.
This post has also been published on the AWS Database blog.
In this post, we show you how to get started with knowledge graphs using the metaphactory platform backed by Amazon Neptune. Offered by AWS Partner Network (APN) Select Technology Partner metaphacts GmbH, metaphactory helps you build knowledge graphs and the smart applications that use them.
Visualize and explore knowledge graphs quickly by connecting metaphactory to Amazon Neptune
Knowledge graphs consolidate and integrate an organization’s information assets and make them more readily available to all members of the organization. There are many applications and use cases that are enabled by knowledge graphs.
Graphs are a natural way to model and represent information about the world. This idea is not new, but has now become more viable via the introduction of scalable graph databases.
Unlike traditional ways of managing data, such as relational databases, graph modeling is very flexible and allows for the real-world diversity and heterogeneity of data. This lets us model complex and complicated subject matter.
For example, suppose a user is interested in works of art by Leonardo da Vinci. As shown in the following figure, a graph allows easy discovery of his works of art, and where in the Louvre museum to find them.

Knowledge graphs have gained prominence in enterprise data management because they offer advantages for data integration and knowledge democratization. They also help build smarter applications that use symbolic artificial intelligence (AI) methods and deliver actionable insights for end users.
In this post, we show you how to get started with knowledge graphs using the metaphactory platform backed by Amazon Neptune.
Offered by AWS Partner Network (APN) Select Technology Partner metaphacts GmbH, metaphactory helps you build knowledge graphs and the smart applications that use them.
Neptune and metaphactory
Neptune is a serverless, fully managed, graph database service built for the cloud that can store property graphs and RDF knowledge graphs of massive scale. It’s a purpose-built graph database service that efficiently stores and navigates highly connected data, and can query billions of relationships with millisecond latency. You can use Neptune to create workloads that support social networks, recommendation engines, fraud detection, knowledge graphs, drug discovery applications, and more.
metaphactory is an end-to-end enterprise knowledge graph platform that transforms your data into consumable, contextual, and actionable knowledge. Operating on top of Neptune, metaphactory adheres to open and FAIR data principles, streamlining the process of capturing and organizing domain expertise within explicit semantic knowledge models. It extracts actionable insights from data and facilitates sharing of knowledge across the entire enterprise.
metaphactory offers a rich knowledge management functionality that knowledge engineers use for data administration, transformation, analysis, and building end-user applications. End-users benefit from a user-friendly interface made for easy search, exploration, navigation visualization, consumption, and management of knowledge.
Features include semantic knowledge modeling, low-code application building, and end-user interaction. These capabilities enable relevant stakeholders to make informed and intelligent business decisions while also promoting the discovery of hidden insights and fostering innovation. The following diagram illustrates the metaphactory platform architecture.

Both Neptune and metaphactory support the W3C Semantic Web standards of SPARQL 1.1 and RDF 1.1.
In a separate case study, you can see how Siemens Energy uses metaphactory and Neptune for their end-user oriented custom knowledge graph application for managing its fleet of large gas turbines.
Solution overview
In this post, we load a sample RDF knowledge graph into Neptune and use metaphactory to search and explore it. The high-level steps are as follows:
-
Create a Neptune cluster.
-
Deploy metaphactory on Amazon Elastic Compute Cloud (Amazon EC2).
-
Configure metaphactory to connect to Neptune.
-
Load data into Neptune using metaphactory.
-
Search and explore the data using metaphactory.
This post is designed for anyone who wants to become familiar with knowledge graphs. You don’t need to have any prior knowledge of the RDF data model or SPARQL query language.
The overall architecture of our setup is depicted in the following diagram, where a Neptune cluster is deployed into a VPC. A Neptune cluster is a collection of instances, with the minimum number being 1. Instances can be serverless for on-demand vertical auto scaling, or distinct instance types. The primary instance acts as the single writer instance, and horizontal scalability is available for read operations, by creating additional read-replica instances. Each cluster comes with a cluster endpoint delegating requests to the writer instance, as well as a reader endpoint distributing (read-only) queries to the read replicas.

To interact with the Neptune cluster, we deploy an EC2 client instance into the same VPC, where security groups are used to configure permissions. In our setup, the metaphactory application acts as a client and is connected to Neptune through its cluster endpoint. This starts a web server that accepts incoming traffic on port 80. You can configure the IP range from which metaphactory is accessible as part of the setup. Use this IP range to restrict access to metaphactory, for example, to a company’s internal network.
Customers are responsible for the costs of running the solution. For help with estimating costs, visit the AWS Pricing Calculator.
Create a Neptune cluster
For instructions on setting up a Neptune cluster, refer to Getting Started with Amazon Neptune.
Deploy metaphactory on Amazon EC2
You can register for a free metaphactory trial on AWS Marketplace by choosing AWS Marketplace at https://metaphacts.com/get-started. The trial confirmation email will provide instructions on how you can access metaphactory on AWS Marketplace.
After you subscribe to metaphactory for Neptune, you will be prompted to use the Amazon EC2 configuration guide to spin up your EC2 instance for metaphactory. To test metaphactory, a t3.medium instance type is sufficient.
In the setup wizard, provide the following:
-
To ensure easy communication between metaphactory and Neptune, provide the VPC that Neptune is running in.
-
Although optional, enabling AWS Identity and Access Management (IAM) database authentication is recommended for production applications. To pair Neptune and metaphactory, refer to Enabling IAM database authentication in Neptune.
-
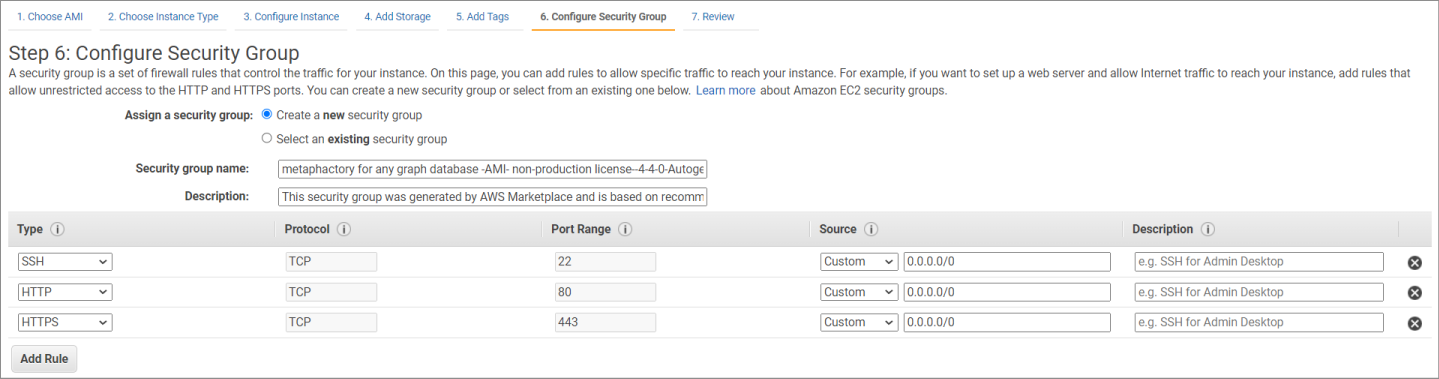
It’s also important to define the security group permissions for your instance. Configure the IP ranges and ports through which you’ll be able to access metaphactory.
All other parameters of the configuration wizard can be left unchanged from the default values.
When you complete the configuration wizard, the EC2 instance with metaphactory will usually be created in under 10 minutes.
Find more information on specifics of configuring EC2 instances to work with Amazon Neptune in the metaphactory documentation.
Configure metaphactory to connect to Neptune
The final step is to configure the connection to Neptune in metaphactory.
-
Log in to metaphactory using admin as your user name and your EC2 instance ID as password.
-
Configure the repository access parameters on the startup page (choose Neptune from the repository preset templates).
-
Provide the read and write SPARQL endpoint URLs.
The Neptune endpoint URLs can be identified on the Neptune console, under cluster settings.
-
Set the IAM DB authentication flag

-
Choose Update Config to connect metaphactory and Neptune.
Load data into Neptune using metaphactory
We use the Nobel Prize dataset provided by the Nobel foundation for our knowledge graph. The Nobel Prize dataset is centered around the Nobel Prize laureates and the awards that they have received.
This Nobel Prize public dataset is licensed under Creative Commons Zero (CC0) and free to use as stated by the Terms & Conditions of the Nobel Prize website.
metaphacts hosts the Nobel Prize dataset in a publicly available Amazon Simple Storage Service (Amazon S3) bucket, which allows us to use the SPARQL UPDATE LOAD command to load the Nobel Prize ontology, vocabulary, and instance data. The metaphacts team has extended the ontology that was originally provided by the Nobel Prize foundation with SHACL shapes, which can be used to validate the data against the schema as defined in the ontology.
-
Choose SPARQL in the menu bar to access the query builder.

-
Enter the following command:
-
Confirm this action, and metaphactory will load all necessary assets from the S3 bucket.
-
To check whether the load operation was successful, navigate to each of the following pages and verify that there’s now at least one entry in each section:
-
Assets, Vocabularies
-
Assets, Ontologies
-
Assets, Datasets
As well as using SPARQL UPDATE LOAD, you can also load data by one of the following metaphactory features:
-
Choose the cloud icon in the application header, then drag and drop the desired data files onto the metaphactory data loading page.
-
Use the user-friendly metaphactory UI/UX that uses the Neptune Bulk Loader. For details, see Loading Data into Amazon Neptune.
Search and explore data with metaphactory
Search is the most common entry point to new data. Out-of-the-box search is available in metaphactory to provide a quick path to knowledge via the search field.
![]()
In the search field, enter the name of any Nobel Prize laureate that comes to mind. For this example, we use Albert Einstein.
There are three default views in which metaphactory exposes data about a resource:
-
Graph (default)
-
Statements
-
Page
Choose the search result to see the graph view about the resource Albert Einstein.

Graph view
The graph view provides an incremental navigation through the graph by following the edges between the nodes; it always starts from the node of the selected resource.
We can open the Connections menu for Albert Einstein and reach Kaiser-Wilhelm-Institut (now Max-Planck-Institut) für Physik through the affiliation connection. By exploring further from here, we find out that Petrus (Peter) Josephus Wilhelmus Debye, who received his Nobel Prize in 1936 in Chemistry, is also affiliated with this university.
Choose the nobelPrize connection in the navigation menu and then add the node of the specific Nobel Prize. You can expand any node on the graph by choosing the plus sign located inside each node on the graph.

The power of knowledge graphs is shown prominently in this example; you can understand the meaning of the data from a quick glance at the graph view.
Statements view
Knowledge about a resource is presented as triples, which is how the data is stored in graph databases. A triple consists of a subject, an object, and a predicate. The selected resource is always the subject, and the object is a fact about the subject related to it via the predicate property.
Statements can be incoming or outgoing. Knowledge and application engineers can use this view when constructing end-user applications, specifically in composing correct SPARQL queries.
The following screenshot illustrates the outgoing statements for Albert Einstein in the Nobel Prize dataset.

Page view
In the page view, you can define a custom view per resource or per group of resources, such as an entire ontology class, by using metaphactory’s templating capabilities.
To learn more about how to create page views, refer to Page View Configuration on the metaphactory website.
In a future post, we will describe in detail how to create page views.
Conclusion
In this post, we showed you how to set up Neptune with the metaphactory platform and use this software stack to explore and search RDF-based knowledge graphs.
We encourage you to try to load your own RDF data into Neptune and explore it with metaphactory. The easiest way to do this is by signing up for a trial on the metaphacts Get Started page (choose the AWS Marketplace trial option). You can use all the exploration techniques discussed in this post to view and query any RDF graph stored in your Neptune database, without any additional configuration.

